
Attention-GAN for Object Transfiguration in Wild Images
Abstract
本文研究了野生图像中的物体变形问题。 用于对象转换的经典 GAN 中的生成网络通常承担双重职责:检测感兴趣的对象并将对象从源域转换到另一个域。 相反,我们将生成网络分解为两个独立的网络,每个网络仅专用于一个特定的子任务。 注意力网络预测图像的空间注意力图,而转换网络专注于翻译对象。 Attention网络产生的特征图更应该是稀疏的,这样就可以将主要注意力放在感兴趣的对象上。 无论在物体变形之前还是之后,注意力图都应该保持不变。 此外,考虑到可用的图像分割注释,学习注意力网络可以接收更多指令。 实验结果证明了在对象转换中研究注意力的必要性,并且所提出的算法可以学习准确的注意力以提高生成图像的质量。
Key words
Generative Adversarial Networks, Attention Mechanism
1. introduction
图像到图像翻译的任务旨在将图像从源域翻译到另一个目标域,例如,灰度图像到彩色图像、图像到语义标签。 许多关于图像到图像翻译的研究都是在监督环境中进行的,目标领域的基本事实是可用的。 [1] 通过最小化生成图像与相应目标图像之间的差异,使用 CNN 学习参数化翻译函数。 [2] 使用条件 GAN 来学习从输入到输出图像的映射。 类似的想法已应用于各种任务,例如从草图或语义布局生成照片 [3、4],以及图像超分辨率 [5]。
为了在没有配对示例的情况下实现图像到图像的转换,通过将经典对抗训练 [6] 与不同的精心设计的约束相结合,出现了一系列工作,例如循环约束 [7-9]、f-consistency 约束 [10] 和距离约束 [11]。尽管有配对的数据,这些约束能够在两个域之间建立联系,从而获得有意义的类似物。 循环约束 [7–9] 需要从一个域到另一个域的样本,该样本可以映射回以生成原始样本。 f-consistency 要求每个域的输入和输出在神经网络的中间空间中应该相互一致。 [11] 通过在源域和目标域中计算的匹配成对距离之间强制执行高跨域相关性,以一种单边无监督的方式学习图像翻译映射。
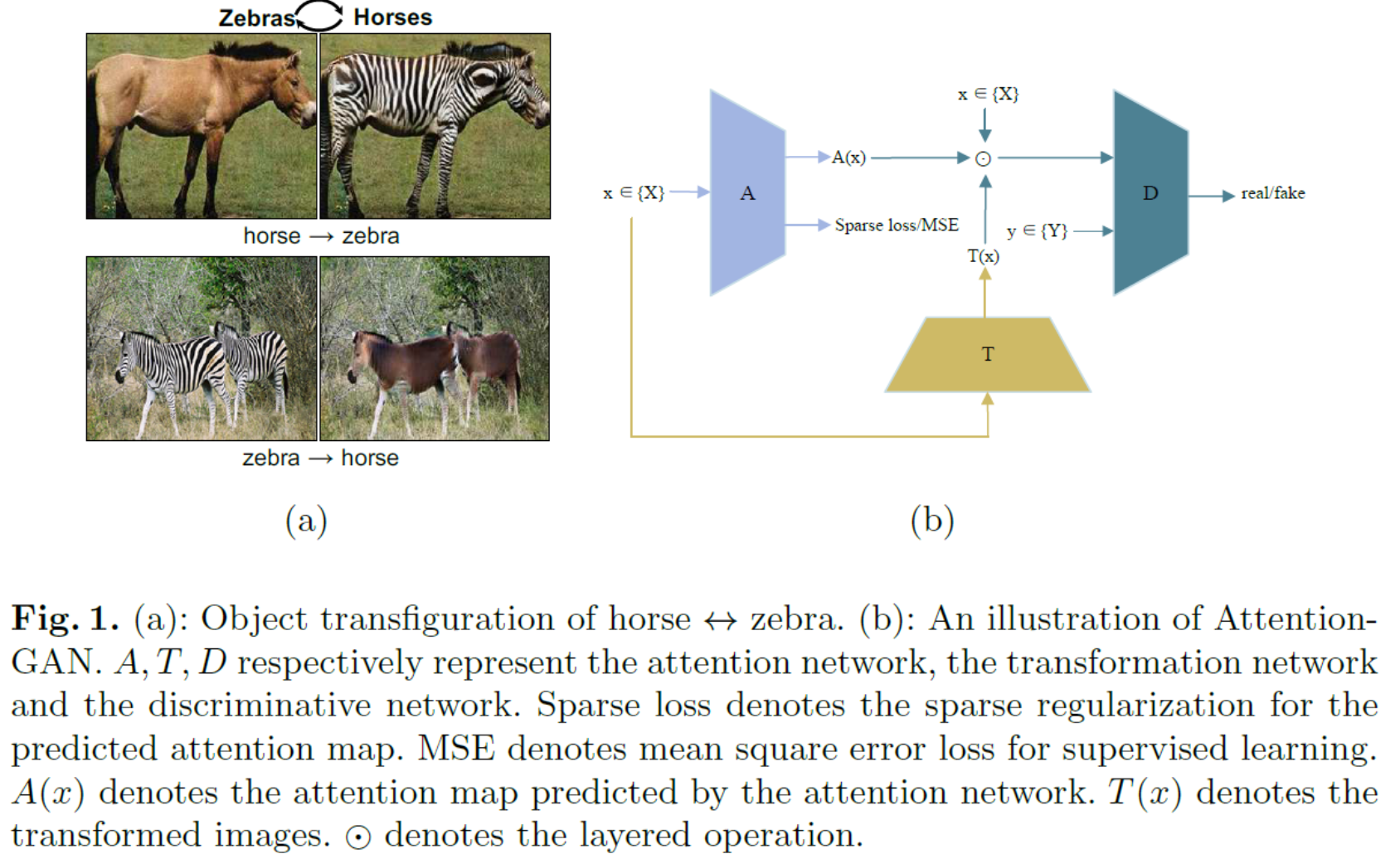
对象变形是图像到图像转换问题中的一项特殊任务。 对象变形不是将图像作为一个整体来完成转换,而是在不影响背景区域的情况下,将图像中特定类型的对象转换为另一种类型的对象。例如,在图1(a)的最上面一行,图像中的马被转化为斑马,斑马被转化为马,但草地和树木预计是不变的。 现有方法 [7、11] 用于将对象变形作为一般的图像到图像任务来处理,而没有研究对该问题的独特见解。 在这样的一次性生成中,生成网络实际上承担了两个不同的角色:检测感兴趣区域和将对象从源域转换为目标域。 然而,将这两个功能合并到一个网络中会混淆生成网络的目标。 在迭代中,可能不清楚生成网络是否应该改进其对感兴趣对象的检测或促进其对对象的变形。 生成图像的质量通常因此受到严重影响,例如 一些背景区域可能会被错误地转换。
在本文中,我们针对对象变形问题提出了一种注意力-GAN 算法。 经典 GAN 中的生成网络被分解为两个独立的网络:一个用于预测注意力应该放在何处的注意力网络,以及一个实际执行对象转换的转换网络。 在注意力图上应用了稀疏约束,因此有限的注意力能量可以集中在优先区域而不是随机分布在整个图像上。 借助学习的稀疏注意力掩码,通过将变换后的对象和原始背景区域组合起来,采用分层操作来最终确定生成的图像。判别网络用于将真实图像与这些合成图像区分开来,而注意网络和转换网络协同生成可以欺骗判别网络的合成图像。 Cycleconsistent loss [7-9] 被用来处理不成对的数据。 此外,如果图像的分割结果可用,则可以以有监督的方式学习注意力网络,并相应地提高所提出算法的性能。 马 ↔ 斑马、老虎 ↔ 豹和苹果 ↔ 橘子 [12] 三个对象变形任务的实验结果表明,在对象变形中研究注意力的优势,以及所提出算法相对于SOTA方法定量和定性的改变。
2. Related Work
GAN 生成对抗网络 (GAN) [6] 通过双人极小极大游戏在图像生成 [13-15] 方面取得了令人瞩目的成果:鉴别器旨在区分生成的图像与真实图像,而生成器旨在 生成逼真的图像来愚弄鉴别器。 已经提出了一系列多阶段生成模型来生成更逼真的图像 [16-18]。 [17] 提出了复合生成对抗网络(CGAN),它通过使用多个生成器生成图像的不同部分来分解图像的复杂因素。 分层递归 GAN [18] 学习分别递归地生成图像背景和前景。GAN 在各种条件图像生成应用中取得了巨大的成功,例如图像到图像的转换 [7-9、19]、文本到图像的生成 [20、21]。 与从噪声变量生成图像的原始 GAN 不同,条件 GAN 根据输入信息(例如类别、图像和文本)合成图像。 [22] 提出了一种 mask-conditional contrast-GAN 架构,通过在训练和测试阶段利用语义注释来分离图像背景与对象语义变化。 然而,很难为大量图像收集分割掩码,尤其是在测试阶段。
Attention Model in Networks 受人类注意力机制理论[23]的启发,注意力机制已成功引入计算机视觉和自然语言处理任务,例如 图像分类[24-26],图像字幕 [27]、视觉问答 [28]、图像分割 [29]。注意力不是将整个图像或序列压缩成静态表示,而是允许模型根据需要关注图像或特征中最相关的部分。 Mnih 等人。 [24] 提出了一种循环网络模型,该模型只能处理图像或视频的一系列区域或位置。 Bahdanau 等人。 [30] 提出了一种注意力模型,在预测机器翻译的目标词时,可以精细加权源句中输入词的重要性。 在此之后,Xu 等人。 [27] 和姚等人。 [31] 分别将注意力模型用于图像字幕和视频字幕。 该模型会自动学习将视线固定在显着物体上,同时在输出序列中生成相应的单词。 在视觉问答中,[28] 使用问题来选择图像的相关区域来计算答案。 在图像生成方面,Gregor 等人。 [32] 提出了一种生成网络结合注意机制与顺序变分自动编码器框架。 生成器关注由真实图像引导的输入图像的较小区域,并一次为图像生成几个像素。 不同的是,我们的方法将注意力机制与 GAN 框架相结合,并在目标域中没有真实图像的情况下产生感兴趣区域。
3. Preliminaries
在image-to-image translation的工作中,我们有两个域X和Y,其中训练样本${x_i}iN\in X,{y_i}_iN\in Y$。我们的目标是学习一个域到另一个域的映射函数$\mathcal:X\rightarrow Y$(比如马到斑马)。判别器$D_Y$要从转换的图像中$\mathcal(x)$区分出真实图像y。相反,映射函数$\mathcal$试图生成看起来与 Y 域中的图像相似的图像$\mathcal(x)$来欺骗鉴别器。 LSGAN [33] 中对抗性损失的目标表示为:
$$
\mathcal\left(\mathcal, D_, X, Y\right)=\mathbb{y \in Y}\left[D_^{2}(y)\right]+\mathbb{x \in X}\left[\left(D_(\mathcal(x))-1\right)^{2}\right] (1)
$$
映射函数$\mathcal: Y\rightarrow X$同样的尝试欺骗判别器$D_X$:
$$
\mathcal\left(\mathcal, D, X, Y\right)=\mathbb{x \in X}\left[D_^{2}(x)\right]+\mathbb{y \in Y}\left[\left(D_(\mathcal(y))-1\right)^{2}\right] (2)
$$
判别器$D_X$和$D_Y$尝试最大化loss而映射函数$\mathcal和\mathcal$尝试最小化loss。然而,具有足够容量的网络可以将输入图像集映射到目标域中图像的任意随机排列。 为了保证学习函数将单个输入 x 映射到期望的输出 y,提出了循环一致性损失来衡量将翻译后的图像带回原始图像空间时发生的差异:
$$
\mathcal(G, F)=\mathbb{x \in X}\left[|\mathcal(\mathcal(x))-x|_{1}\right]+\mathbb{y \in Y}\left[|\mathcal(\mathcal(y))-y|_{1}\right] (3)
$$
利用对抗损失和循环一致性损失,该模型实现了一对一的对应映射,并发现了跨域关系[8]。 完整的目标是:
$$
\begin
\mathcal\left(\mathcal, \mathcal, D, D_\right) &=\mathcal\left(\mathcal, D
&+\mathcal, X, Y\right) \\left(\mathcal, D, Y, X\right)+\lambda \mathcal_(\mathcal, \mathcal)
\end (4)
$$
其中λ控制两个目标的相对重要性。 然而,生成映射函数 G 和 F 实际上承担了对象转换的双重责任:检测感兴趣的对象和转换对象,这混淆了生成网络的目标。
另一方面,我们注意到该模型可以被视为两个“自动编码器”:F ◦G : X → X 和 G ◦F : Y → Y,其中转换后的图像 G(x) 和 F(y) 可以是 被视为由对抗损失训练的中间表示。在对象变形任务中,生成映射 G 和 F 被训练来生成对象来欺骗鉴别器。 因此,图像背景可以编码为任意表示,只要能解码回原图即可,不保证变换前后背景的一致性。 因此,所提出的 Attention-GAN 将生成网络分解为两个分离的网络:一个用于预测感兴趣对象的注意力网络和一个专注于转换对象的转换网络。
4. Model
所提出的模型由三个参与者组成:注意力网络、转换网络和判别网络。 注意力网络从原始图像 x 预测感兴趣区域。 转换网络专注于将对象从一个域转换到另一个域。 因此,生成的图像是通过分层运算实现经过变换的对象和原始图像的背景的组合。 最后,鉴别器旨在区分真实图像 y ∈ Y 和生成图像。 所提出模型的概述如图 1(b) 所示。 为了符号简单,我们只展示了将图像从域 X 变换到域 Y 的前向过程,从域 Y 回到域 X 的后向过程可以用类似的方法很容易地获得。
4.1 Formulations
所提出模型的架构如图 2 所示。给定域 X 中的输入图像 x,注意网络 $A_X$输出空间得分图 $A_X(x)$,其大小与原始图像 x 相同。 score map 的元素值从 0 到 1。注意网络在抑制背景的同时,将较高分数的视觉注意力分配给感兴趣的区域。 在另一个分支中,转换网络 T 输出看起来与目标域 Y 中的图像相似的转换图像 T(x)。然后我们采用分层操作重建最终图像,给定变换区域 $A_X(x)$,变换图像 $T_X(x)$ 和原始图像 x 的图像背景组合为:
$$
\mathcal(x) \equiv A_(x) \odot T_(x)+\left(1-A_(x)\right) \odot x (5)
$$
其中$\odot$表示逐元素乘法运算符。 引入另一个映射函数$\mathcal$将变换后的图像$\mathcal(x)$带回原始空间 $\mathcal(\mathcal(x))\approx x$。 从目标域 Y 中的图像 y 到源域的映射如下:
$$
\mathcal(y) \equiv A_(y) \odot T_(y)+\left(1-A_(y)\right) \odot y (6)
$$
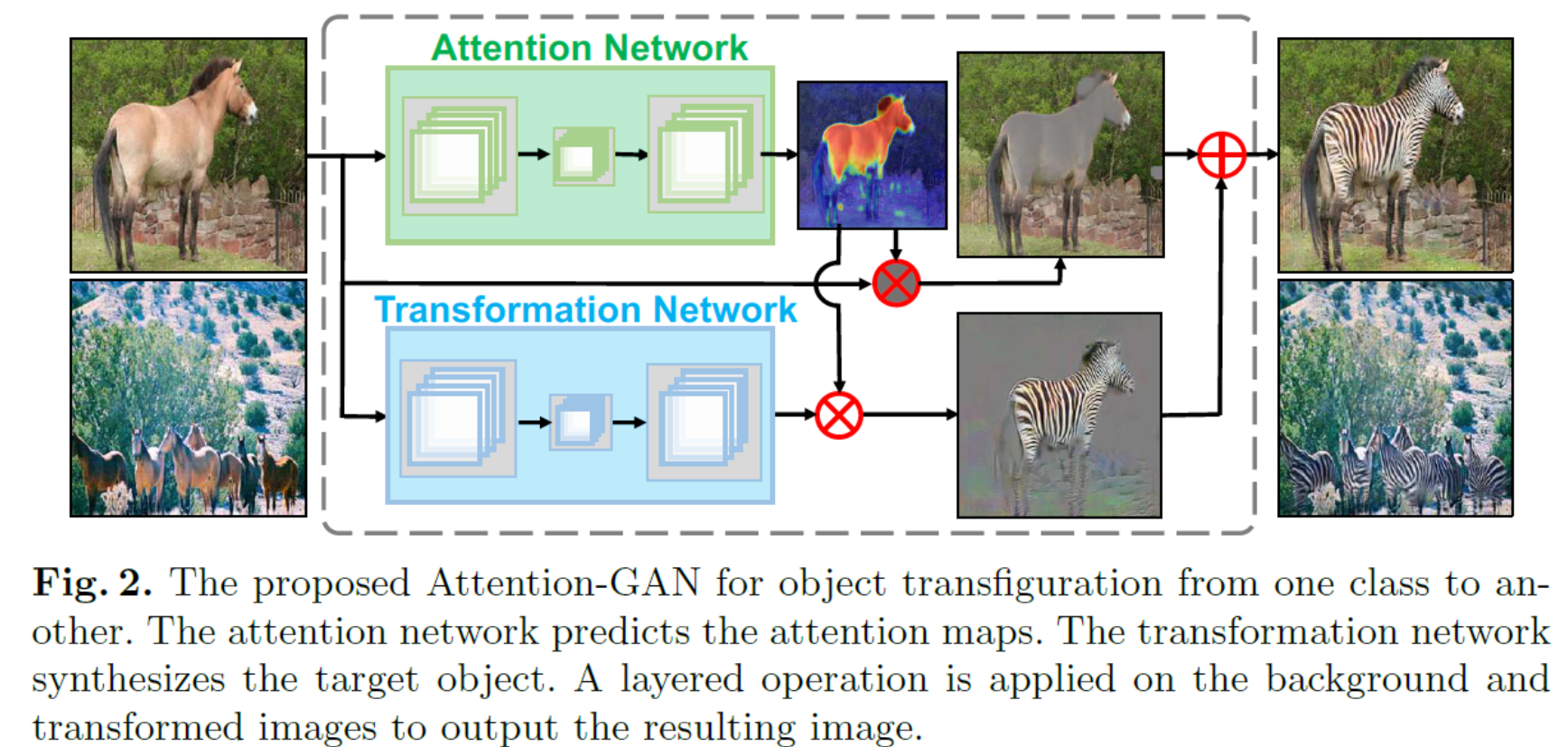
在第 3 节之后,引入了对抗损失(等式(1)和(2))和循环一致性损失(等式(3))来学习整体映射 G 和 F。在经典 GAN [7-9] 中, 生成映射 G 将整个图像变换到目标域,然后需要生成映射 F 将变换后的图像恢复为原始图像 F (G (x)) ≈ x。 然而,在实践中,生成图像的背景看起来不真实,与原始图像背景明显不同,因此循环一致性损失很难达到 0。在我们的方法中,注意力网络输出一个掩码,将图像分离成 感兴趣的区域和背景。 背景部分不做变换,使背景中的循环一致性损失达到0。
4.2 Attention Loss
类似于循环一致性,注意力网络$A_X$预测的域X中对象x的注意力图应该与注意力网络$A_Y$变换后的对象的注意力图一致。 例如,如果一匹马变成了斑马,斑马在经过一个循环后应该可以再变成马。 也就是说,原始图像中感兴趣的区域和变换后的图像应该相同:$A_X(x)\approx A_Y(\mathcal(x))$。类似地,对于来自域 Y 的每个图像 y,注意网络 $A_Y$ 和 $A_X$ 应满足一致性:$A_Y(y)\approx A_X(\mathcal(y))$。 为此,我们提出了attention cycle-consistent的损失:
$$
\mathcal{A{\text }}\left(A_, A_\right)=\mathbb{x \in X}\left[\left|A_(x)-A_(\mathcal(x))\right|_{1}\right]+\mathbb{y \in Y}\left[\left|A_(y)-A_(\mathcal(y))\right|_{1}\right] (7)
$$
此外,我们引入了稀疏损失来使得注意力网络关注和物体相关的小区域而不是整张图像:
$$
\mathcal{\text }\left(A, A_\right)=\mathbb{x \in X}\left[\left|A_(x)\right|_{1}\right]+\mathbb{y \in Y}\left\left|A_(y)\right|_{1}\right
$$
考虑到等式(7),$A_X(\mathcal(y))$ 和 $A_Y(\mathcal(x))$ 的注意力图应该与 AY(y) 和 AX(x) 一致,因此它们不包括 $A_X(\mathcal(y))$和 $A_Y(\mathcal(x))$。因此,通过结合等式(1-3)、(7)和(8),我们的全部目标是:
$$
\begin
\mathcal\left(T_, T_, D_, D_, A_, A_\right)=\mathcal\left(\mathcal, D, X, Y\right)+\mathcal\left(\mathcal, D
\quad+\lambda_, X, Y\right) \ \mathcal(\mathcal, \mathcal)+\lambda{A_{\text }} \mathcal{A{\text }}\left(A_, A_\right)+\lambda_{\text } \mathcal{\text }\left(A, A_\right) + \lambda_{A_L_{A_}(A_X,A_Y)},
\end
$$
其中 $\lambda_$ 和 $\lambda_$平衡了不同项的相对重要性。 X域和Y域的注意力网络、转换网络和判别网络可以在下面的min-max博弈中求解:
$$
\arg \min {T, T_, A_, A_} \max {D, D_} \mathcal\left(T_, T_, D_, D_, A_, A_\right)
$$
优化算法在补充材料中被描述。
4.3 Extra Supervision
在某些情况下,可以收集分割注释并将其用作注意力图。 比如我们的马→斑马图像分割出来的马就是感兴趣区域。 因此,我们通过分割标签来监督注意力网络的训练。 给定 N 个示例的训练集 $(x_1,m_1),...(x_N,m_N)$,其中 $m_i$ 表示分割的二进制标签,我们最小化预测注意力图 $A(x_i)$ 和分割标签 $m_i$之间的差异 。为了学习 X 域和 Y 域的注意力图,总的注意力损失可以写成:
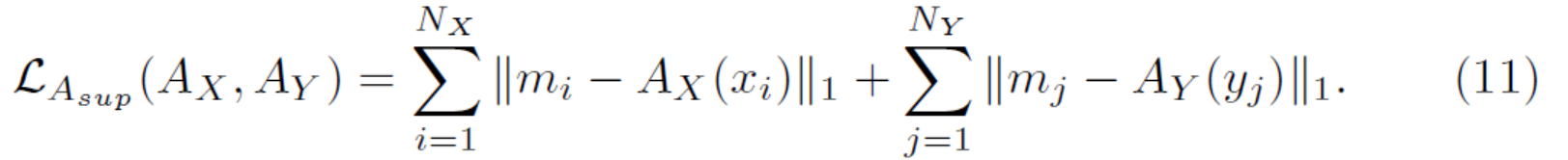
整体的目标变成:
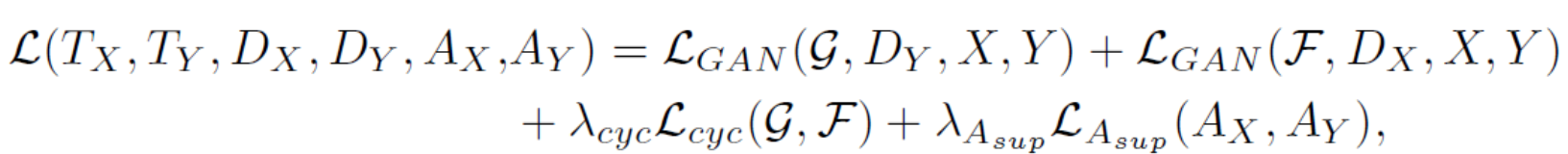
其中 $\lambda_$ 和 $\lambda_{A_}$ 控制目标的相对重要性。 由于注意力图是由语义注释监督的,我们没有结合等式(7)和(8)的约束。
5. Experiments
在本节中,我们首先介绍两个指标来评估生成图像的质量。 然后我们将无监督的 Attention-GAN 与 CycleGAN [7] 进行比较。 接下来,我们研究注意力稀疏损失的重要性,并将我们的方法与一些变体进行比较。 最后,我们展示了受监督的 Attention-GAN 的实证结果。
我们首先在三个任务上评估了拟议的 Attention-GAN:马 ↔ 斑马、老虎 ↔ 豹和苹果 ↔ 橙子。 马、斑马、苹果和橙子的图像由 CycleGAN [7] 提供。 老虎和豹子的图像来自ImageNet [12],其中包括1,444张老虎图像和1,396张豹子图像。 我们随机选择了 60 张图片进行测试,其余的作为训练集。 在监督实验中,我们执行了马 ↔ 斑马任务,其中可以从 MSCOCO 数据集 [34] 获得图像和注释。 对于每个对象类别,MSCOCO 训练集中的图像用于训练,MSCOCO 验证集中的图像用于测试。 对于所有实验,训练样本首先缩放为 286×286,然后随机翻转裁剪为 256×256。 在测试阶段,我们将输入图像缩放到 256 × 256 的大小。
对于所有实验,网络在前 100 个时期以 0.0002 的初始学习率和在接下来的 100 个时期变为零的线性衰减率进行训练。 我们使用批量大小为 1 的 Adam 求解器 [35]。我们使用从先前生成的图像缓冲区中随机选择的样本更新了判别网络,然后是 [36]。 训练过程在补充材料中展示。 转换网络和注意力网络的架构基于 Johnson 等人。 [37]。 判别器改编自 Markovian Patch-GAN [38、2、7、9]。 补充材料中列出了详细信息。
5.1 Assessment of Image Quality
由于需要对象变形来预测感兴趣区域并在保留背景的同时变换对象,我们引入度量来估计变换图像的质量。
为了评估变换的背景一致性,我们计算生成图像背景和原始图像背景之间的 PSNR 和 SSIM。PSNR 是人类对重建质量感知的近似值,它是通过均方误差 (MSE) 定义的。 给定测试样本 $(x_1,m_1),...(x_N,m_N)$,我们使用分割掩码的逐像素乘法 ⊙ 来计算图像背景 PSNR:
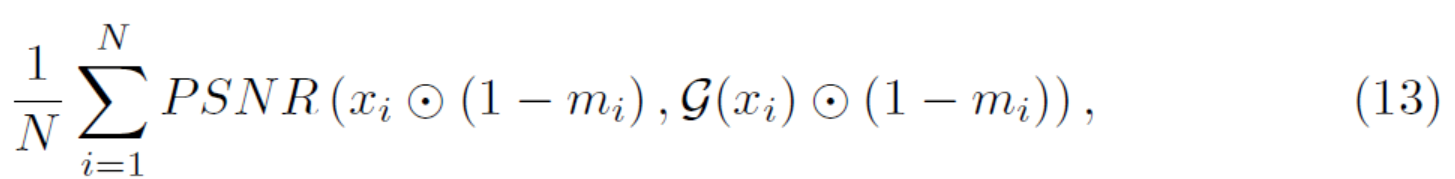
其中 $x_i$ 表示原始图像,$\mathcal(x_i)$表示结果图像,(1 − mi) 表示图像背景,像素乘法 xi ⊙ (1 − mi) 表示原始图像的背景,$\mathcal(x_i)$ ⊙ (1 − mi) 表示生成图像的背景。 同样地,我们通过逐像素相乘使用SSIM来评估原始图像和合成输出之间的结构相似性。

在实验中,我们使用MSCOCO数据集中的测试图像和分割mask来评估生成图像的背景质量。
5.2 Unsupervised Results Comparisions to SOTA

Quantitative Comparison. 我们通过计算图像背景的PNSR和SSIM比较了我们的方法和CycleGAN、DistanceGAN,由于MSCOCO 数据集没有tiger和leopard类,并且图像中的apples和oranges太小,我们只比较horse ↔ zebra的结果。 结果如表 1 所示。可以看出,对于 PSNR 和 SSIM,我们在无监督方式下的方法优于 CycleGAN 和 DistanceGAN,这表明所提出的模型预测准确的注意力图并实现了更好的转换质量性能。 由于我们的方法大大优于 DistanceGAN,因此我们仅使用 CycleGAN 探索定性质量和人类感知研究。
Qualitative Comparison. 马 ↔ 斑马的结果如图 4 所示。我们观察到,与 CycleGAN 相比,我们的方法在测试数据上提供了更高视觉质量的翻译结果。 比如在马→斑马任务中,CycleGAN错误的把背景中的一部分当成目标,并且把他们变成黑白条纹。在图 4 的第二列中,CycleGAN 在斑马→马任务中将绿色的草地和树木转化为棕色。 相反,我们的方法在正确的位置生成斑马纹并保持背景的一致性。 tiger ↔ leopard 和 apple ↔ orange 的对比结果如图 5 所示。Attention-GAN 的结果比 CycleGAN 的视觉效果更佳。 在大多数情况下,CycleGAN 无法保持背景的一致性,例如,第一张图像中的蓝色牛仔裤变成黄色,第三张图像中的蓝色水变成黄色,最后一张图像中的黄色杂草变成绿色。 一个可能的原因是我们的 Attention-GAN 通过注意力网络解开了背景和感兴趣的对象,只对对象进行了变换,而比较方法只使用一个生成网络来操纵整个图像。
Human Perceptual Study. 我们通过人类研究进一步评估我们的算法。 我们执行部署在 Amazon Mechanical Turk 平台上的成对 A/B 测试。 我们遵循 [39、40] 中相同的实验程序。 要求参与者从每对图像中选择更逼真的图像。 每对包含通过两种方法从同一源图像翻译而来的两幅图像。 我们测试了马 ↔ 斑马、老虎 ↔ 豹和苹果 ↔ 橘子的任务。 在每个任务中,我们从测试集中随机选择 100 张图像。 每张图片由 10 名参与者进行比较。 图 6 显示了参与者在 100 个示例中的偏好。我们观察到我们方法的 92 个结果优于 CycleGAN 在 horse ↔ zebra 任务中的结果。 在 tiger ↔ leopard 中,比较方法仍然只有 17% 的结果打败了我们的,这表明我们提出的方法获得的定性评估优于现有方法获得的定性评估。我们还注意到,在 apple ↔ orange 任务中,我们的方法只有 60 个结果 方法优于比较方法。 我们认为原因是 apple 和 orange 数据集中的大部分图像是背景简单的特写图像,因此 CycleGAN 可以达到有竞争力的结果.
5.3 Model Analysis
我们对马→斑马任务进行模型分析。 图 7 显示了生成的图像,以及模型的中间生成结果。在第二列,显示了注意力图。 可以看出,在完全不受监督的情况下,模型的注意力网络能够成功地从输入图像中分离出我们感兴趣的对象和背景。第三列是转换网络的输出,其中转换后的斑马在视觉上令人愉悦,而图像的背景部分则毫无意义。 它表明转换网络仅专注于转换感兴趣的对象。 此外,图 7 显示最后一列中的最终输出图像由第四列中的背景部分和第五列中的感兴趣对象组合而成。
图 8 显示了我们的模型变体在马→斑马上的定性结果。 可以看出,如果没有稀疏损失(等式(8)中的稀疏= 0),注意力网络会将图像背景的某些部分预测为感兴趣区域。 当 sparse 设置为 5 时,attention mask 缩小太多而无法覆盖整个感兴趣的对象。 这是因为如果我们过分强调稀疏损失的相对重要性,注意力网络就不能全面地预测物体位置。 我们发现 $\lambda_$=1 是一个合适的选择,它很好地平衡了对兴趣对象的足够关注。在表 2 中,我们观察到随着稀疏值变大,背景一致性的性能更好。 但是,如果稀疏设置太大,则转换对象的质量会降低。 这表明稀疏度可以被视为平衡背景一致性和转换质量性能的参数。
5.4 Comparisons of Supervised Results
我们在 horse ↔ zebra 任务中计算生成图像和原始图像之间背景区域的 PSRN、SSIM。 在表 1 中,从背景一致性的角度来看,带监督的 Attention-GAN 优于无监督的 Attention-GAN 和 CycleGAN。 这表明注意力网络使用分割掩码可以更准确地预测感兴趣的对象。 在图 9 中,CycleGAN 和无监督的 Attention-GAN 将人的某些部位预测为感兴趣区域,并将其转换为斑马纹(见图 9 第一行)。 我们还注意到,有监督的注意力图往往是深红色或深蓝色,这表明有监督的注意力网络预测的置信度更高,并且更清楚地分离背景和兴趣对象。
我们根据 UoI 和 mAPr@0.5 评估马的前景掩码。无监督的 Attention-GAN 获得了 28.1% 的 UoI 和 20.3% 的 mAPr@0.5。另一方面,有监督的Attention-GAN获得37.8%的UoI分数和30.5的mAP@0.5。虽然我们的算法不是专门为语义分割而设计的,但所提出的注意力网络能够以无监督的方式学习感兴趣的对象并取得合理的性能。
5.5 Global Image Transformation
局部和全局图像变换都很重要。 我们研究物体变形,并在马 ↔ 斑马、苹果 ↔ 橘子和老虎 ↔ 豹上进行评估。 更多的应用包括虚拟试穿 [41] 关于一个人想要的衣服项目,以及改变面部属性(例如胡须和眼镜)[42]。 所提出的注意力 GAN 可以有效地识别对象变形问题中的重要区域,并且还可以在全局图像变换中产生一些有趣的观察结果。 在夏季 ↔ 冬季,没有明确的兴趣对象,但算法确实识别出一些更受关注的区域,例如 图10中的草和树,通常在夏天是绿色的,在冬天是棕色的。 同时,没有明显特征的区域,例如蓝天将不会被关注。
6. Conclusion
本文将注意力机制引入考虑图像上下文和对象变形任务结构信息的生成对抗网络中。 我们开发了一个由注意力网络、转换网络和判别网络组成的三人模型。 注意网络预测感兴趣的区域,而转换网络将对象从一个类别转换为另一个类别。 我们表明,我们的模型在保持背景一致性和转换质量方面优于一次性生成方法 [7]。