
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Abstract
与近年来大规模vision transformer(ViTs)的巨大进步相比,基于卷积神经网络(CNNs)的大规模模型仍处于早期状态。 这项工作提出了一种新的基于 CNN 的大规模基础模型,称为 InternImage,它可以从增加参数和训练数据(如 ViTs)中获得收益。 不同于最近专注于大密集卷积核的CNN。InternImage 以可变形卷积为核心算子,使我们的模型不仅具有检测和分割等下游任务所需的大有效感受野,而且具有以输入和任务信息为条件的自适应空间聚合。因此,所提出的 InternImage 减少了传统 CNN 的严格归纳偏差,并使得从 ViT 等海量数据中学习具有大规模参数的更强、更鲁棒的模式成为可能。 我们模型的有效性在具有挑战性的基准测试中得到了证明,包括 ImageNet、COCO 和 ADE20K。值得一提的是,InternImage-H 在 COCO test-dev 上取得了 65.4 mAP 的新纪录,在 ADE20K 上取得了 62.9 mIoU 的新纪录,优于目前领先的 CNN 和 ViT。
1. introduction
随着transformers在大规模语言模型[3-8]中取得的显著成功,vision transformers(ViTs)[2, 9-15]也席卷了计算机视觉领域,正成为大规模语言模型研究和实践的首选。一些先前工作 [16-20] 已经尝试将 ViT 扩展到具有超过十亿个参数的非常大的模型,击败了卷积神经网络(CNNs)并且极大推动了一系列计算机视觉任务的表现极限。包括基本的分类、检测和分割。虽然这些结果表明 CNN 在海量参数和数据时代不如 ViT,我们认为,基于 CNN 的基础模型在配备了类似的运算符/架构级设计、扩展参数和大规模数据时可以取得和VIT相当甚至更好的表现。
为了弥合 CNN 和 ViT 之间的差距,我们首先从两个方面总结它们的差异:(1) 从算子级别 [9, 21, 22],ViT 的多头自注意力 (MHSA) 具有长程依赖性 和自适应空间聚合(见图1(a))。 受益于灵活的 MHSA,ViT 可以从海量数据中学习比 CNN 更强大、更稳健的表征。 (2) 从体系结构的角度来看[9,22,23],除了MHSA,ViTs还包含一系列标准CNNs中没有的高级组件,如层归一化(LN)[24]、前馈网络(FFN) ) [1]、GELU [25] 等。尽管最近的工作 [21,22] 通过使用具有非常大的内核(例如 31 31)的密集卷积对将长程依赖性引入 CNN 进行了有意义的尝试,如中所示 图 1 (c),在性能和模型规模方面与最先进的大规模 ViTs [16, 18–20, 26] 仍有相当大的差距。
在这项工作中,我们专注于设计一个基于 CNN 的基础模型,该模型可以有效地扩展到大规模参数和数据。 具体来说,我们从灵活的卷积变体开始——可变形卷积 (DCN) [27, 28]。 通过将其与一系列类似于 transformer 的定制块级和架构级设计相结合,我们设计了一个全新的卷积骨干网络,称为 InternImage。 如图 1 所示,不同于最近改进的具有非常大内核的 CNN,例如
$$31\times 31$$
[22]InternImage 的核心运算符是一个动态稀疏卷积,其公共窗口大小为
$$3\times 3$$
,(1) 其采样偏移灵活,可以从给定数据中动态学习适当的感受野(可以是长程或短程); (2)采样偏移量和调制标量根据输入数据自适应调整,可以像ViTs一样实现自适应空间聚合,减少常规卷积的过度归纳偏差; (3) 卷积窗口为普通的
$$3\times 3$$
,避免了大dense kernel带来的优化问题和昂贵的代价。
通过上述设计,所提出的 InternImage 可以有效地扩展到大参数大小并从大规模训练数据中学习更强的表示,在广泛的视觉范围内实现与大规模 ViTs [2、11、30] 相当甚至更好的性能 任务。总之,我们的主要贡献如下:
(1) 我们提出了一种新的基于 CNN 的大规模基础模型——InternImage。 据我们所知,它是第一个有效扩展到超过 10 亿个参数和 4 亿张训练图像的 CNN,并实现了与最先进的 ViTs 相当甚至更好的性能,表明卷积模型也是一个值得探索的模型 大尺度模型研究方向
(2) 我们通过使用改进的
$$3\times 3$$
DCN 算子引入远程依赖和自适应空间聚合,并探索以算子为中心的定制基本块、堆叠规则和缩放策略。 这些设计有效地利用了运算符,使我们的模型能够从大规模参数和数据中获得收益。成功地将 CNN 扩展到大规模设置
(3) 我们在图像分类、目标检测、实例和语义分割等代表性视觉任务上评估了所提出的模型,并通过将模型大小从 3000 万扩展到最先进的 CNN 和大规模 ViT 进行了比较 到10亿,数据从100万到4亿不等。 具体来说,我们具有不同参数大小的模型可以始终优于 ImageNet [31] 上的现有技术。InternImageB 仅在 ImageNet-1K 数据集上训练就达到了 84.9% 的 top-1 准确率,比基于 CNN 的对应 [21, 22] 至少高出 1.1 个百分点,借助大规模参数(即 10 亿)和训练数据(即 4.27 亿),InternImage-H 的 top-1 准确率进一步提升至 89.6%,接近工程效果比较好的 ViTs [2, 30] 和混合 ViTs [20]。 此外,在具有挑战性的下游基准 COCO [32] 上,我们最好的模型 InternImage-H 以 21.8 亿个参数实现了最先进的 65.4% box mAP,比 SwinV2-G [16] 高 2.3 个百分点(65.4 比 .63.1),参数减少 27%,如图 2 所示
2.相关工作
视觉基础模型。 在大规模数据集和计算资源可用之后,卷积神经网络(CNN)成为视觉识别的主流。 来自 AlexNet [33] 的应变,许多更深的和更有效的神经网络结构被提出,例如 VGG [34]、GoogleNet [35]、ResNet [36]、ResNeXt [37]、EfficientNet [38、39] 等。除了架构设计之外,更复杂的卷积运算如深度卷积 [40] ]和可变形卷积[27、28]被制定。 通过考虑transformer的先进设计,现代 CNN 通过在宏观/微观设计中发现更好的组件并引入具有长程依赖性 [21、41–43] 或动态权重的改进卷积,在视觉任务上表现出了良好的表现。
近年来,一种新的视野基础模型侧重于基于变压器的架构。 ViT [9] 是最具代表性的模型,由于全局感受野和动态空间聚合,它在视觉任务中取得了巨大成功。 然而,ViT 中的全局注意力受到昂贵的计算/内存复杂性的影响,尤其是在大型特征图上,这限制了它在下游任务中的应用。为了解决这个问题,PVT [10, 11] 和 Linformer [45] 对下采样的键和值映射进行了全局关注,DAT [46] 使用可变形的注意力来从值映射中稀疏采样信息,而 HaloNet [47] 和 Swin transformer [2] 开发了局部注意力机制,并使用haloing和移位操作在相邻局部区域之间传递信息。
大型模型。 放大模型是提高特征表示质量的重要策略,这在自然语言处理 (NLP) 领域已得到充分研究 [48]。 受到 NLP 领域成功的启发,Zhai 等人。 [19] 首先将 ViT 扩展到 20 亿个参数。刘等人。 [16] 将层次结构 Swin transformer 扩大到更深更宽的模型,有 30 亿个参数。一些研究人员通过结合 ViTs 和 CNNs 在不同层次的优势,开发了大规模混合 ViTs [20, 49]。 最近,BEiT-3 [17] 使用多模态预训练进一步探索了基于 ViT 的具有大规模参数的更强表示。这些方法显着提高了基本视觉任务的上限。 然而,基于 CNN 的大规模模型的研究在参数总数和性能方面落后于基于 Transformer 的架构。 尽管新提出的 CNN [21, 41–43] 通过使用具有非常大内核的卷积或递归门控内核引入了长程依赖性,但与最先进的 ViT 仍然存在相当大的差距。 在这项工作中,我们的目标是开发一个基于 CNN 的基础模型,该模型可以有效地扩展到与 ViT 相当的大规模。
3.提出方法
为了设计基于 CNN 的大规模基础模型,我们从灵活的卷积变体开始,即可变形卷积 v2 (DCNv2) [28],并基于它进行一些调整以更好地适应大规模基础模型的要求。 然后,我们通过将调谐卷积运算符与现代骨干网中使用的高级块设计相结合来构建基本块 [16, 19]。 最后,我们探索基于 DCN 的块的堆叠和缩放原理,以构建可以从海量数据中学习强表示的大规模卷积模型
3.1 DCNV3
卷积与 MHSA。 以前的工作 [21、22、50] 已经广泛讨论了 CNN 和 ViT 之间的差异。 在决定InternImage的核心算子之前,我们先总结一下regular convolution和MHSA的主要区别。
(1)远程依赖。 尽管人们早就认识到具有较大有效感受野(长程依赖性)的模型通常在下游视觉任务上表现更好 [51-53],但实际上[34,36] 由
$$3\times 3$$
个regular convolutions级联在一起的CNN的有效感受野
比较小。 即使使用非常深的模型,基于 CNN 的模型仍然无法获得像 ViTs 这样的远程依赖,这限制了它的性能
(2)自适应空间聚合。 与权重由输入动态调节的 MHSA 相比,常规卷积 [54] 是一种具有静态权重和强归纳偏差(例如 2D 局部性、邻域结构、平移等价性等)的算子。具有高度归纳特性,由以下组成的模型 与 ViT 相比,常规卷积可能收敛得更快并且需要更少的训练数据,但它也限制了 CNN 从网络规模数据中学习更通用和更稳健的模式
重温 DCNv2。 弥补卷积和 MHSA 之间差距的一种直接方法是将远程依赖和自适应空间聚合引入常规卷积中。让我们从 DCNv2 [28] 开始,它是常规卷积的一般变体,给定输入
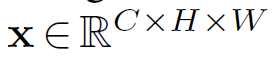
对于每个像素p0,DCNV2可以表示为:
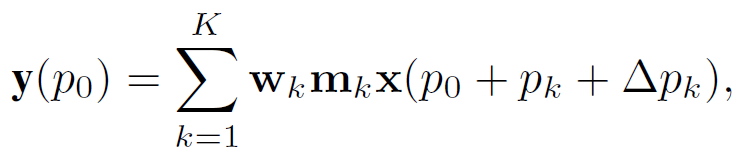
其中K代表采样点总数,k依次表示每个采样点,
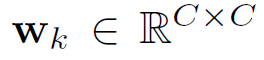
表示第k个采样点的映射权重,
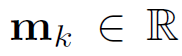
表示第k个采样点的调节因子,它由 sigmoid 函数归一化。
pk 表示预定义网格采样的第 k 个位置,采样
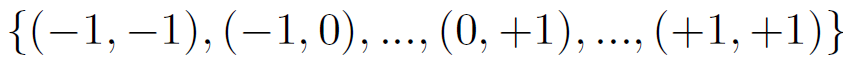 作为常规卷积,Δpk为第k个网格采样位置对应的偏移量。 我们从等式中看出 (1) 对于长程依赖,采样偏移Δpk灵活可变,可以和短程和长程特征交互,(2) 对于自适应空间聚合,采样偏移量 Δpk 和调制标量 mk 都是可学习的,并且由输入 x 调节。 因此可以发现 DCNv2 与 MHSA 具有相似的有利特性,这促使我们在此算子的基础上开发大规模的基于 CNN 的基础模型。
作为常规卷积,Δpk为第k个网格采样位置对应的偏移量。 我们从等式中看出 (1) 对于长程依赖,采样偏移Δpk灵活可变,可以和短程和长程特征交互,(2) 对于自适应空间聚合,采样偏移量 Δpk 和调制标量 mk 都是可学习的,并且由输入 x 调节。 因此可以发现 DCNv2 与 MHSA 具有相似的有利特性,这促使我们在此算子的基础上开发大规模的基于 CNN 的基础模型。
为 Vision Foundation 模型扩展 DCNv2。 在通常的实践中,DCNv2通常被用作常规卷积的扩展,加载常规卷积的预训练权重并进行微调以获得更好的性能,这并不完全适合需要从头开始训练的大规模视觉基础模型 . 在这项工作中,为了解决这个问题,我们从以下几个方面扩展了 DCNv2:
(1) 在卷积神经元之间共享权重。 与常规卷积类似,原始 DCNv2 中的不同卷积神经元具有独立的线性投影权重,因此其参数和内存复杂度与采样点总数成线性关系,这极大地限制了模型的效率,尤其是在大规模模型中。 为了解决这个问题,我们借鉴了可分离卷积 [55] 的思想,并将原始卷积权重 wk 分离为深度部分和点部分,其中深度部分由原始位置感知调制标量 mk 负责 , point-wise 部分是采样点之间共享的投影权重 w
(2) 引入多组机制。 多组(head)设计最早出现在group convolution[33]中,广泛应用于transformer的MHSA[1]中,与自适应空间聚合一起有效地从不同位置的不同表示子空间中学习到更丰富的信息。受此启发,我们将空间聚合过程分成 G 个组,每个组都有单独的采样偏移Δpgk 和调制尺度 mgk,因此单个卷积层上的不同组可以有不同的空间聚合模式,从而为下游提供更强的特征 任务
(3) 沿采样点归一化调制标量。 原始 DCNv2 中的调制标量由 sigmoid 函数按元素归一化。 因此,每个调制标量都在[0, 1]范围内,所有样本点的调制标量之和不稳定,在0到K之间变化。这导致在大规模训练时DCNv2层的梯度不稳定 参数和数据。 为了缓解不稳定问题,我们将 element-wise sigmoid 归一化更改为沿样本点的 softmax 归一化。 这样,调制标量的和被约束为1,使得模型在不同尺度下的训练过程更加稳定
结合上述修改,扩展的 DCNv2,标记为 DCNv3,可以表示为 Eqn(2).
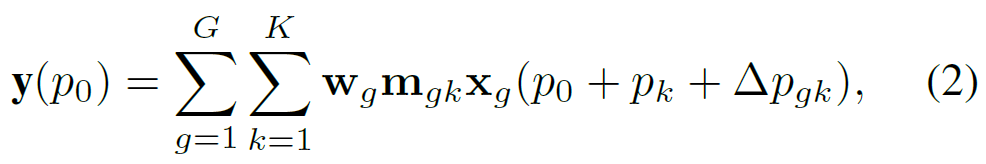
其中 G 表示聚合组的总数。对于第 g 组,
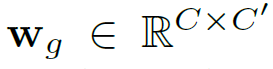 表示组的位置无关投影权重,其中
表示组的位置无关投影权重,其中
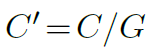
表示组维度。
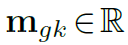
表示第g组中第k个采样点的调制标量,沿维度K由softmax函数归一化。
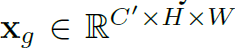
表示切片输入特征图。
Δpgk为第g组中网格采样位置pk对应的偏移量。总的来说,DCNv3作为DCN系列的延伸,具有以下三个优点:
(1) 这种操作弥补了常规卷积缺少长程依赖关系的缺点和自适应的空间聚合,(2) 与常见的 MHSA 和密切相关的可变形注意力 [46, 56] 等基于注意力的算子相比,该算子继承了卷积的归纳偏置,使我们的模型更高效,训练数据更少,训练时间更短; (3) 该算子基于稀疏采样,比以前的方法如 MHSA [1] 和重新参数化大内核 [22] 具有更高的计算和内存效率。 此外,由于采样稀疏,DCNv3 只需要一个
$$3\times 3$$
kernel 来学习 long-range dependencies,更容易优化,避免了大 kernel 中使用的 reparameterizing [22] 等额外的辅助技术。
3.2 InterImage 模型
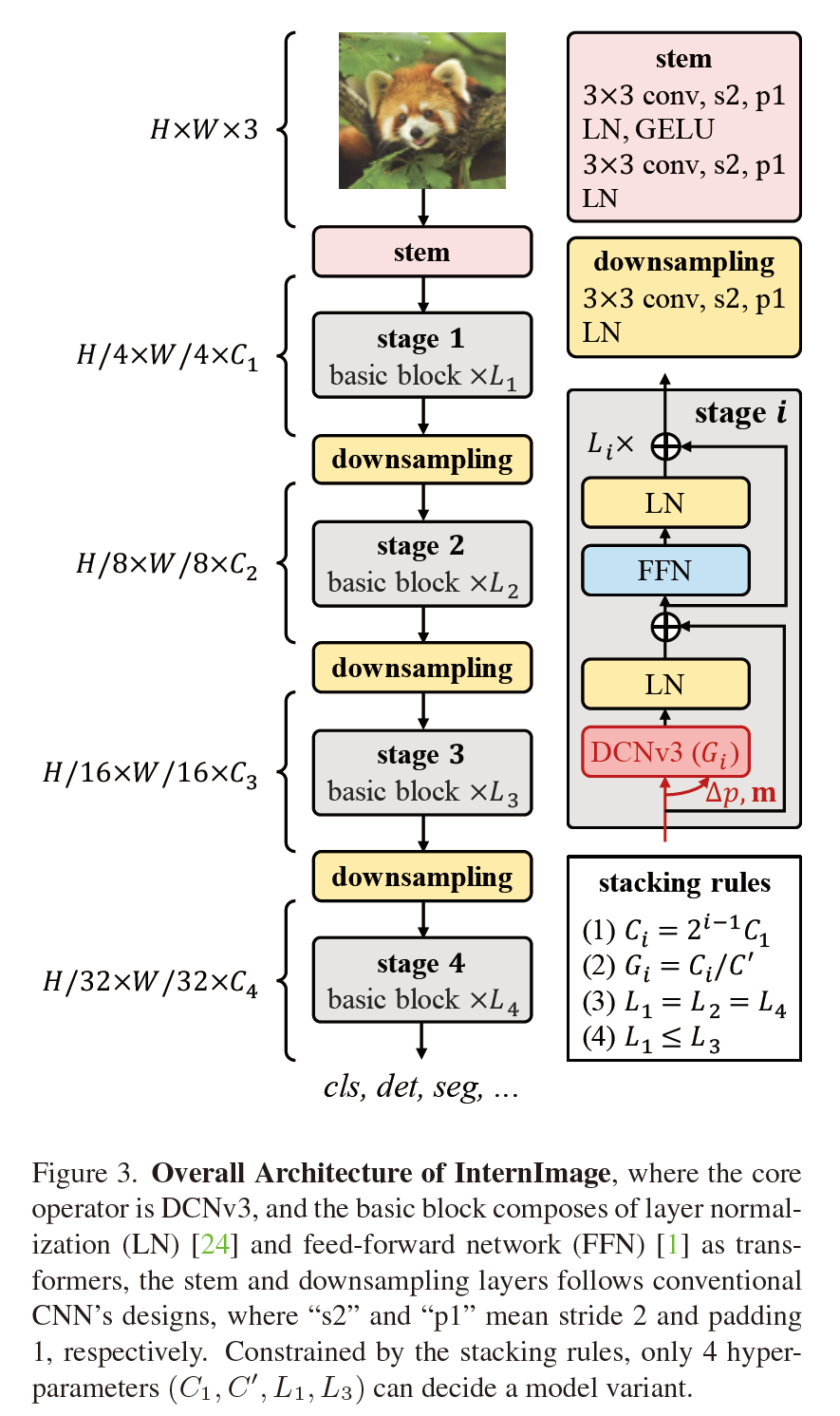
使用DCNv3作为核心算子带来了一个新的问题:如何构建一个能够有效利用核心算子的模型? 在本节中,我们首先介绍模型的基本块和其他整体层的细节,然后通过探索为这些基本块量身定制的堆叠策略,构建一个名为 InternImage 的新的基于 CNN 的基础模型。 最后,我们研究了所提出模型的放大规则,以获得增加参数的增益。
basic block。 与传统 CNN [36] 中广泛使用的BottleNeck不同,我们的基本块的设计更接近 ViTs,它配备了更高级的组件,包括 LN [24]、前馈网络 (FFN) [1] 和 GELU [ 25]。 这种设计在各种视觉任务中被证明是有效的 [2, 10, 11, 21, 22]。 我们的基本块的详细信息如图 3 所示,其中核心算子是 DCNv3,采样偏移量和调制尺度是通过可分离卷积(3×3深度卷积后跟线性投影)传递输入特征 x 来预测的。 对于其他组件,我们默认使用后归一化设置 [57],并遵循与普通变压器相同的设计.
Stem & downsampling layers。 为了获得分层特征图,我们使用卷积干和下采样层将特征图调整为不同的比例。 如图 3 所示,stem 层放置在第一阶段之前,将输入分辨率降低了 4 倍。 它由两个卷积、两个LN层和一个GELU层组成,其中两个卷积的核大小为3,步长为2,填充为1,第一个卷积的输出通道是第二个的一半 . 类似地,下采样层由步长为 2、填充为 1 的3×3卷积组成,后面是一个 LN 层。 它位于两个阶段之间,用于将输入特征图下采样 2 倍。
stacking rules 为了弄清block级联的过程,我们首先列举了InternImage的积分超参数如下:
Ci: 第i个阶段的通道数
Gi: DCNV3第i个阶段的组数目
Li: 第i个阶段的基本block数目
由于我们的模型有 4 个阶段,一个变体由 12 个超参数决定,其搜索空间太大而无法穷举并找到最佳变体。 为了减少搜索空间,我们将现有技术[2,21,36]的设计经验总结为4条规则,如图3所示,其中第一条规则使后三级的通道数由通道数C1决定 第一阶段的,第二个规则让组号对应于阶段的通道数。 对于不同阶段的堆叠块数,我们将堆叠模式简化为“AABA”,即第1、2、4阶段的块数相同,且不大于第3阶段的块数,如图所示 最后两条规则,用这些规则,一个InternImage的变体可以用四个超参数(C1,C',L1,L3)定义。
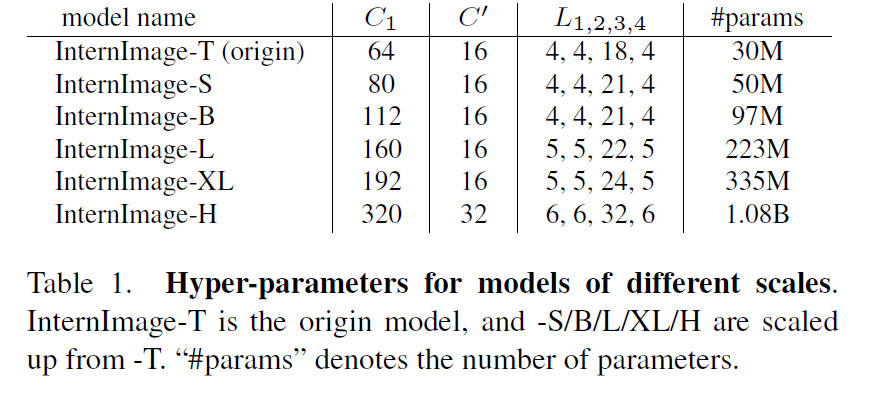
让我们选择一个具有 3000 万个参数的模型作为原点,并将 C1 到{48,64,80}离散化; L1至{1,2,3,4,5};C'到{16,32}离散化。 这样,原来巨大的搜索空间减少到 30 个,我们可以在 ImageNet [31] 中通过训练和评估从这 30 个变体中找到最好的模型。 在实践中,我们使用最佳超参数设置(64,16,4,18)来定义原点模型并将其缩放到不同的尺度。
Scaling rules 基于上述约束下的最优原点模型,我们进一步探索受[38]启发的参数缩放规则。 具体来说,我们考虑两个缩放维度:深度 D(即 3L1+L3)和宽度 C1,并使用α、β和复合因子Φ缩放两个维度,缩放规则可以写成:
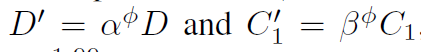 ,其中α≥1,β≥1,
,其中α≥1,β≥1,
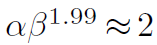
此处,1.99 特定于 InternImage,通过将模型宽度加倍并保持深度不变来计算。 我们通过实验发现最佳的缩放比例设置为α=1.09和β=1.36,然后我们以此为基础构建不同参数比例的InternImage变体,即InternImage-T/S/B/L/XL,其复杂度与 ConvNeXt [21] 相似。 为了进一步测试该能力,我们构建了一个更大的具有 10 亿个 参数的 InternImage-H,并且为了适应非常大的模型宽度,我们还将组维度 C0 更改为 32。配置总结在表 1 中。
4. 实验
我们分析并比较了 InternImage 与领先的 CNN 和 ViT 在图像分类、目标检测、实例和语义分割等代表性视觉任务上的表现。 除了主要论文中的实验外,由于空间限制,补充材料中介绍了更多的实验设置和消融研究
4.1 图像分类
图像分类设置。 我们评估了 InternImage 在 ImageNet [31] 上的分类性能。 为了公平比较,按照常见做法 [2,10,21,58],InternImage-T/S/B 在 ImageNet-1K(130 万)上训练 300 个 epoch,InternImage-L/XL 首先在 ImageNet 上训练 -22K(1420 万)90 轮,然后在 ImageNet-1K 上微调 20 轮,为了进一步探索我们模型的能力并匹配以前方法 [16、20、59] 中使用的大规模私有数据,我们采用 M3I 预训练 [60],一种可用于未标记和弱标记的统一预训练方法 标记数据,在公共 Laion-400M [61]、YFCC-15M [62] 和 CC12M [63] 的 4.27 亿联合数据集上预训练 InternImage-H 30 个时期,然后我们微调模型 在 ImageNet1K 上进行 20 个 epoch。
结果。 表2显示了不同尺度模型的分类结果。 凭借相似的参数和计算成本,我们的模型与最先进的基于 transformer 和 CNN 的模型相当,甚至更胜一筹。 例如,InternImage-T 达到了 83.5% 的 top-1 准确率,明显优于 ConvNext-T [21] 1.4 个百分点。InternImage-S/B 保持领先地位,InternImage-B 超过 hybridViT CoAtNet-2 [20] 0.8 个百分点。 当在 ImageNet-22K 和大规模联合数据集上进行预训练时,InternImage-XL 和 -H 的 top-1 精度分别提高到 88.0% 和 89.6%,优于之前的 CNN [22,67] 还使用大规模数据进行训练,并将与最先进的大规模 ViT 的差距缩小到约 1 个点。 这种差距可能是由于大规模不可访问的私人数据与上述联合公共数据之间的差异造成的。 这些结果表明我们的InternImage不仅在通用参数尺度和公共训练数据上有很好的性能,而且可以有效扩展到大规模参数和数据。
4.2 目标检测
设置我们在 COCO 基准测试 [32] 和两个最有代表性的目标检测框架上验证了我们的 InternImage 的检测性能,Mask RCNN [70] 和 Cascade Mask R-CNN [71]。 我们遵循常见做法 [2, 11] 使用预训练的分类权重初始化主干,训练模型默认使用 1(12 个时期)或 3(36 个时期)时间表。
结果 如表 3 所示,当使用 Mask RCNN 进行对象检测时,我们发现在相当数量的参数下,我们的模型明显优于它们的对应模型。 例如,在第 1 个训练计划中,InternImage-T 的 box AP (APb) 比 Swin-T [2] 高 4.5 个点(47.2 vs. 42.7),比 ConvNeXt-T [21] 高 3.0 个点( 47.2 对 44.2)。通过 3倍数多尺度训练计划、更多参数和更先进的 Cascade Mask R-CNN [71],InternImage-XL 的 APb 达到 56.2,超过 ConvNeXt-XL 1.0 分(56.2 vs.
55.2). 在实例分割实验中也可以看到类似的结果。 使用 1 训练计划,InternImage-T 产生 42.5 mask AP(即 APm),分别优于 SwinT 和 ConvNeXt-T 3.2 分(42.5 对 39.3)和 2.4 分(42.5 对 40.1)。最好的 APm 48.8 是由 InternImage-XL with Cascade Mask R-CNN 获得的,比其对应的至少高出 1.1 个点。
为了进一步突破目标检测的性能界限,我们遵循领先方法 [16、17、26、74、78] 中使用的高级设置,使用在 ImageNet-22K 或大规模联合上预训练的权重初始化主干 数据集,并通过复合技术将其参数加倍 [78](参见图 2 中具有 20 亿个参数的模型)。然后我们用DINO检测器在Object365上微调,COCO数据集依次为26个epoch和12个epoch。 如表 4 所示,我们的方法在 COCO val2017 和 test-dev 上取得了 65.0 APb 和 65.4 APb 的最佳结果,与之前的最先进模型相比,我们比 FD-SwinV2-G [26] 高出 1.2 个百分点(65.4 对 64.2),参数减少了 27%,并且没有复杂的蒸馏过程,这表明我们模型的有效性 在检测任务上