
Abstract
卷积和自注意力是表征学习的两种强大的技术,它们通常被认为是两种截然不同的对等方法。在本文中,我们证明了它们之间存在很强的潜在关系,即这两种范式的大部分计算实际上是用相同的操作完成的。具体来说,我们首先证明了核大小为k × k的传统卷积可以分解为k^2个单独的1×1卷积,然后是移位和求和操作。然后,我们将自关注模块中的查询、键和值的投影解释为多个1×1卷积,然后计算关注权重和值的聚合。因此,两个模块的第一阶段包含类似的操作。更重要的是,与第二阶段相比,第一阶段的计算复杂度(通道大小的平方)占主导地位。这种观察自然导致了这两种看似不同的范式的优雅集成,即一个混合模型,它既享受自注意和卷积(ACmix)的好处,又与纯卷积或自注意相比具有最小的计算开销。大量的实验表明,我们的模型在图像识别和下游任务的竞争基线上取得了持续改进的结果。代码和预训练模型将在https://github.com/LeapLabTHU/ACmix和https://gitee.com/mindspore/models上发布。
1. Introduction
近年来,卷积和自关注在计算机视觉领域取得了巨大的发展。卷积神经网络(cnn)在图像识别、语义分割和目标检测被广泛采用,并在各种基准上实现最先进的性能。另一方面,自注意首先被引入到自然语言处理中[1,43],在图像生成和超分辨率领域也显示出巨大的潜力[10,35]。最近,随着vision transformer的出现[7,16,38],基于注意力的模块在许多视觉任务上取得了与CNN相当甚至更好的性能。
尽管这两种方法都取得了巨大的成功,但卷积和自关注模块通常遵循不同的设计范式。传统卷积根据卷积滤波器权值在局部接受域上利用聚合函数,这些权值在整个特征映射中共享。内在特征对图像处理施加了关键的归纳偏差。相比之下,自关注模块采用基于输入特征上下文的加权平均操作,其中关注权重通过相关像素对之间的相似性函数动态计算。这种灵活性使注意力模块能够自适应地关注不同的区域,并捕获更多信息特征。
考虑到卷积和自注意的不同和互补性质,仍然存在一种可能性通过集成这些模块来从中受益,以前的工作从几个不同的角度探索自注意力和卷积的结合,SENet[23]、CBAM[47]等早期研究表明,自注意机制可以作为卷积模块的一种增强。最近,自关注模块被提出作为单独的块来替代CNN模型中的传统卷积,例如SAN [54], BoTNet[41]。另一项研究侧重于将自我注意和卷积结合在单个块中,例如AA-ResNet [3],Container,而该体系结构在为每个模块设计独立路径方面受到限制。因此,现有的方法仍然将自注意和卷积视为不同的部分,并且它们之间的潜在关系没有得到充分利用。
在本文中,我们试图揭示自注意力和卷积之间更密切的关系。通过分解这两个模块的操作,我们发现它们严重依赖于相同的1×1卷积操作。基于这一观察,我们开发了一个名为ACmix的混合模型,并以最小的计算开销优雅地集成了自注意力和卷积。具体来说,我们首先使用1×1卷积投影输入特征映射,并获得丰富的中间特征集。然后,按照不同的范式,即分别以自注意力和卷积的方式对中间特征进行重用和聚合。通过这种方式,ACmix可以享受两个模块的优势,并有效地避免进行两次昂贵的投影操作。
总结起来,我们的共享主要在两方面:
(1)揭示了自注意力与卷积之间的强烈潜在关系,为理解两个模块之间的联系提供了新的视角,并为设计新的学习范式提供了灵感。
(2)提出了一种将自注意力模块与卷积模块完美结合的方法,同时兼顾了两者的优点。经验证据表明,混合模型始终优于纯卷积模型或自注意模型
2. Related Work
卷积神经网络[27,28]使用卷积核提取局部特征,已成为各种视觉任务中最强大和最传统的技术[20,25,40]。同时,自注意力在BERT和GPT3等广泛的语言任务中也表现出了普遍的表现[4,14,37]。理论分析[11]表明,当具备足够大的容量时,自注意力可以表示任意卷积层的函数类。因此,最近的一系列研究探索了在视觉任务中采用自注意机制的可能性[16,23]。有两种主流的方法,一种是使用自注意力在网络中作为构建模块,另一种是把自注意力和卷积视为互补部分。
2.1 Self-Attention only
受到自注意力在远程依赖中的表达能力的启发[14,43],一系列工作试图将自注意力作为构建视觉任务模型的基本构建模块[2,7,16]。一些研究[38,54]表明,自注意力可以成为视觉模型的独立原语,完全替代卷积操作。最近,Vision Transformer[16]表明,给定足够的数据,我们可以将图像视为256个令牌的序列,并利用Transformer模型[43]在图像识别中获得有竞争力的结果。此外,在检测[2,7,57]、分割[46,53,55]、点云识别[18,33]等视觉任务[8,35]中采用了transformer范式。
2.2 Attention enhanced Convolution
先前提出的多个图像注意机制表明,它可以克服卷积网络的局部性限制。因此,许多研究者探索了使用注意模块或利用更多的关系信息来增强卷积网络功能的可能性。特别是,squeeze -and - dexcitation (SE)[23]和Gather-Excite (GE)[22]重新衡量了每个通道的地图。BAM[34]和CBAM[47]分别对通道和空间位置进行重新加权,以更好地细化特征图。AA-Resnet[3]通过连接来自另一个独立的自注意管道的注意图来增强某些卷积层。BoTNet[41]在模型的后期阶段用自关注模块替代卷积。一些工作旨在设计一个更灵活的特征提取器,通过从更大范围的像素聚集信息。Hu等[21]提出了一种基于局部像素组成关系自适应确定聚合权值的local-relation方法。Wang等人提出了非局部网络[45],该网络通过引入非局部块来比较全局像素之间的相似性,从而增加了接受域。
2.3 Convolution enhanced Attention
随着vision transformer[16]的出现,许多基于transformer的变体被提出,并在计算机视觉任务上取得了重大改进。其中已有的研究主要集中在用卷积运算来补充transformer模型,以引入额外的归纳偏置。CvT[48]在标记化过程中采用卷积,并利用跨步卷积来降低自注意的计算复杂度。带有卷积干的ViT[50]提出在早期加入卷积以实现更稳定的训练。CSwin Transformer[15]采用了基于卷积的位置编码技巧并显示了下游任务的改进。Conformer[36]将Transformer与一个独立的CNN模型相结合,实现了两者的融合。
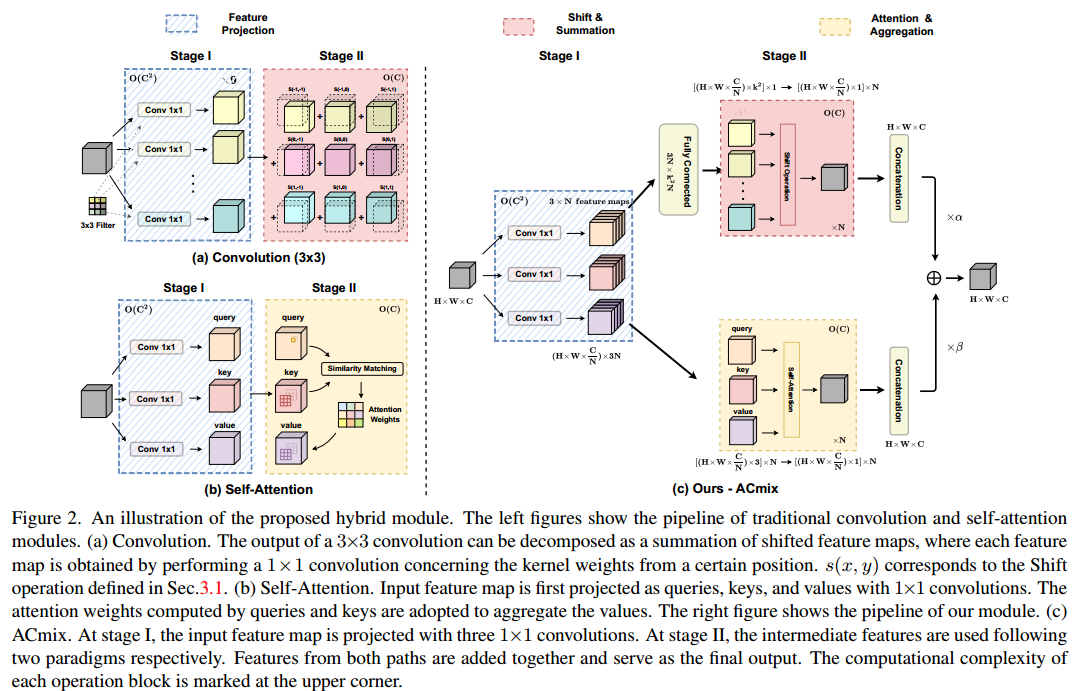
3. Revisiting Convolution and Self-Attention
卷积和自关注以其当前的形式已经广为人知。为了更好地捕捉这两个模块之间的关系,我们通过将它们的操作分解为不同的阶段,从一个新的角度重新审视它们。
3.1 Convolution
卷积是现代卷积神经网络中最重要的部分之一。我们首先回顾标准卷积运算,并从不同的角度重新表述它。如图2(a)所示。为简单起见,我们假设卷积的步幅为1。
考虑卷积核为K的标准卷积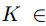
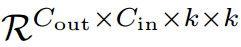 ,其中k是卷积核大小,Cin, Cout是输入和输出通道大小,给定向量
,其中k是卷积核大小,Cin, Cout是输入和输出通道大小,给定向量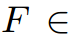
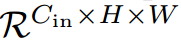 ,
,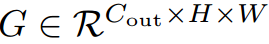 为输入和输出特征映射,其中H, W表示高度和宽度,我们用
为输入和输出特征映射,其中H, W表示高度和宽度,我们用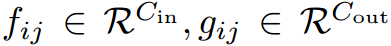 表示对应F和G的特征向量像素(i,j)。然后,标准卷积可以用公式表示成:
表示对应F和G的特征向量像素(i,j)。然后,标准卷积可以用公式表示成:
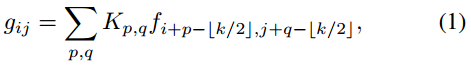 ,其中
,其中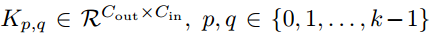 表示相对于核位置(p, q)指标的核权值。
表示相对于核位置(p, q)指标的核权值。
为方便起见,我们可以将Eq.(1)重写为不同核位置的特征映射的和:
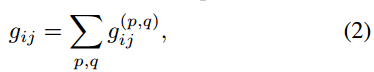 ,其中:
,其中:
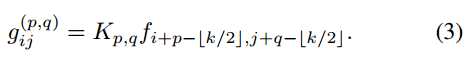
为了进一步简化公式,我们定义了Shift操作,
 作为:
作为:
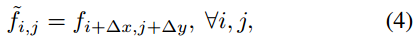
其中,∆x,∆y分别为水平位移和垂直位移。则式(3)可改写为:
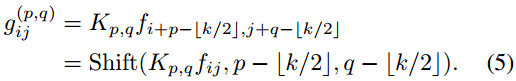
因此,标注卷积可以概括为两个阶段:
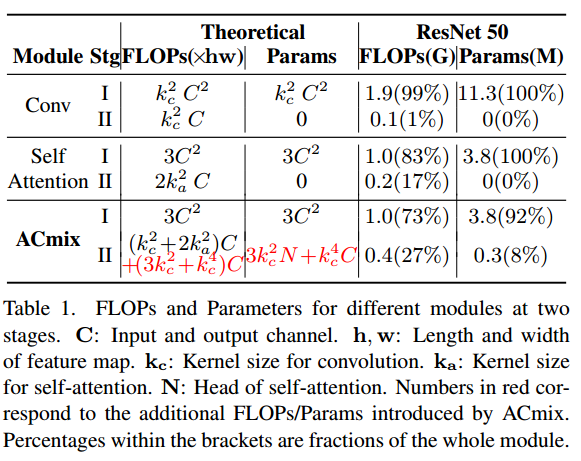
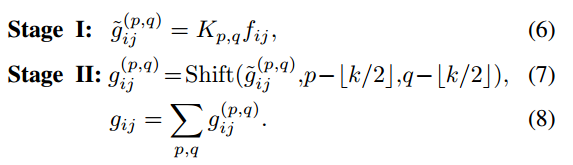
在第一阶段,输入特征映射从某一位置(即(p, q)开始,对核权值进行线性投影,这与标准的1 × 1卷积相同。在第二阶段,将投影的特征映射根据核的位置进行移动,最终聚合在一起。可以很容易地观察到,大部分计算成本是在1×1卷积中执行的,而接下来的移位和聚合则是轻量级的。
3.2 Self-Attention
注意机制在视觉任务中也被广泛采用。与传统的卷积相比,注意力允许模型专注于更大范围内的重要区域。我们在图2(b)中展示了例证。考虑一个有N个头的标准自注意力模块,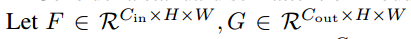 表示输入和输出特征,
表示输入和输出特征,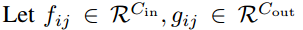 表示对应的像素点(i,j),然后注意力模块可以计算为:
表示对应的像素点(i,j),然后注意力模块可以计算为:
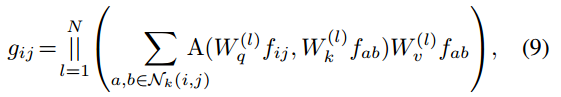
其中||是N个注意力头的串联,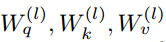 是查询、键和值的投影矩阵。Nk(i, j)表示以(i, j)为中心,空间范围为k的像素局部区域,并且
是查询、键和值的投影矩阵。Nk(i, j)表示以(i, j)为中心,空间范围为k的像素局部区域,并且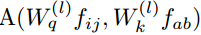 为Nk(i, j)内特征对应的注意权值。
为Nk(i, j)内特征对应的注意权值。
对于文献[21,38]中广泛采用的自注意模块,注意权值计算为: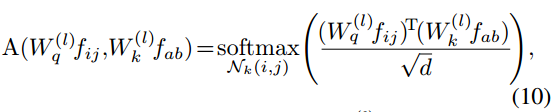
式中d为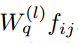 的特征维数。
的特征维数。
多头自我注意也可以分解为两个阶段,重新表述为:
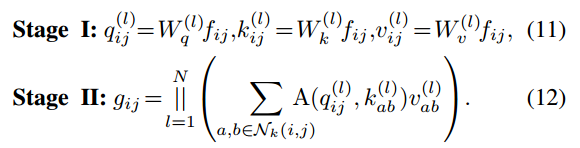 与3.1节中的传统卷积类似,在第一阶段首先进行1×1卷积,将输入特征投影为query、key和value。另一方面,第二阶段是计算关注权值和对值矩阵进行聚合,即收集局部特征。与阶段1相比,相应的计算成本也被证明是较小的,遵循与卷积相同的模式。
与3.1节中的传统卷积类似,在第一阶段首先进行1×1卷积,将输入特征投影为query、key和value。另一方面,第二阶段是计算关注权值和对值矩阵进行聚合,即收集局部特征。与阶段1相比,相应的计算成本也被证明是较小的,遵循与卷积相同的模式。
3.3 Computation Cost
为了充分了解卷积和自关注模块的计算瓶颈,我们对每个阶段的浮点运算(FLOPs)和参数数量进行了分析,并总结如表1所示。结果表明,第一阶段的理论FLOPs和参数对通道大小C具有二次复杂度,而第二阶段的计算成本与C呈线性关系,不需要额外的训练参数。
自注意模块也发现了类似的趋势,其中所有训练参数都保留在阶段1。至于理论FLOPs,我们考虑在resnet类模型中的正常情况,其中对于不同的层深度,ka = 7和C = 64, 128, 256, 512。明确地表明,当3C 2 > 2k 2 aC时,阶段I消耗的操作更重,并且随着通道大小的增加,差异更明显。
为了进一步验证我们分析的有效性,我们还总结了ResNet50模型中卷积和自关注模块的实际计算成本,如表1所示。我们实际上将所有3×3卷积(或自关注)模块的成本加起来,以从模型的角度反映趋势。结果表明,在第一阶段进行了99%的卷积计算和83%的自我注意,这与我们的理论分析一致。
4. Method
4.1 Relating Self-Attention with Convolution
在第3节中对自注意模块和卷积模块的分已经从多个角度揭示了深层关系,首先,这两个阶段的作用非常相似。第一阶段是特征学习模块,两种方法通过执行1×1卷积将特征投影到更深的空间来共享相同的操作。另一方面,第二阶段对应于特征聚合过程,尽管他们在学习范式上存在差异。从计算的角度来看,卷积和自关注模块在第一阶段进行的1 × 1卷积都需要理论FLOPs和参数相对于通道大小c的二次复杂度,相比之下,在第二阶段两个模块都是轻量级的或几乎不需要计算。综上所述,以上分析表明:(1)卷积和自关注在通过1×1卷积投影输入特征映射上的操作实际上是相同的,这也是两个模块的计算开销。(2)尽管对于捕获语义特征至关重要,但阶段II的聚合操作是轻量级的,不需要获取额外的学习参数。
4.2 自注意力和卷积的结合
上述观察结果自然会导致卷积和自我关注的完美结合。由于两个模块共享相同的1×1卷积操作,因此我们只能执行一次投影,并将这些中间特征映射分别用于不同的聚合操作。我们提出的混合模块ACmix的示意图如图2(c)所示。
具体来说,ACmix还包括两个阶段。在第一阶段,输入特征通过三个1×1卷积进行投影,并分别重构为N个片段。因此,我们获得了一组丰富的中间特征,其中包含3×N特征映射。
在第二阶段,它们遵循不同的范式使用。对于自注意路径,我们将中间特征收集到N组中,其中每组包含三个特征,每个1×1卷积一个。对应的三个特征映射作为查询、键和值,遵循传统的多头自注意力模块(Eq.(12))。对于核大小为k的卷积路径,我们采用轻量的全连接层,生成k^2个特征映射。因此,通过移动和聚合生成的特征(Eq.(7),(8)),我们以卷积方式处理输入特征,并像传统方式一样从局部接受场收集信息。
最后,将两条路径的输出加在一起,强度由两个可学习的标量控制:
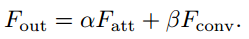
4.3 Improved Shift and Summation
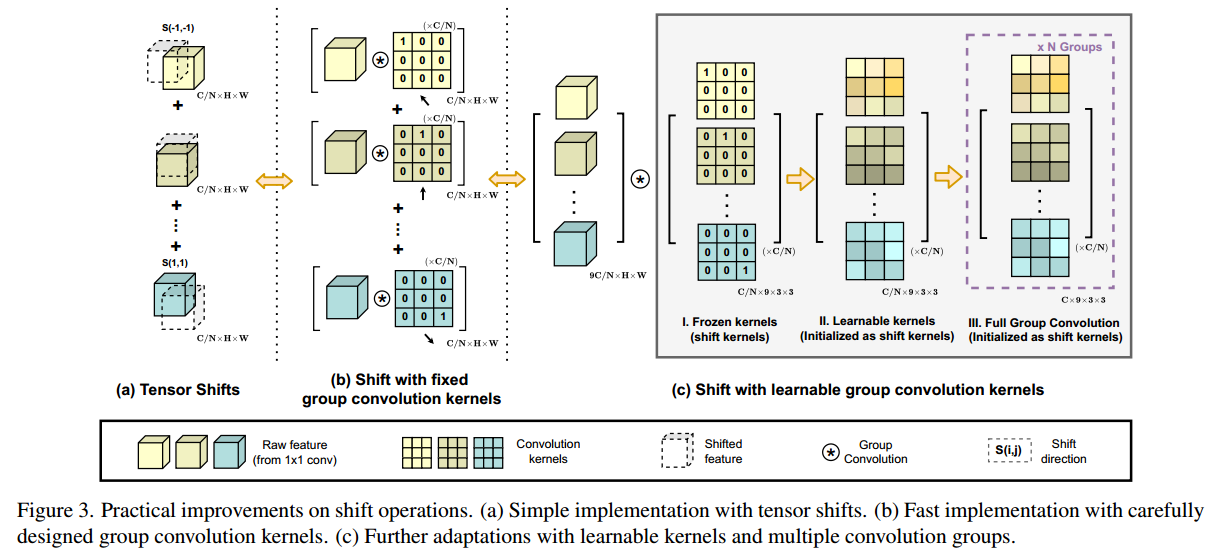
如图4.2和图2所示,卷积路径中的中间特征遵循传统卷积模块中的移位和求和操作。尽管理论上它们是轻量级的,但向不同方向移动张量实际上破坏了数据局部性,并且难以实现向量化实现。这可能会极大地损害我们模块在推理时的实际效率。
作为补救措施,我们采用固定核深度卷积来替代低效张量位移,如图3 (b)所示。以Shift(f,−1,−1)为例,位移特征计算为:
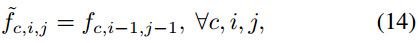
其中c表示输入特征的每个通道。
另一方面,如果我们表示卷积核(kernel size k=3):
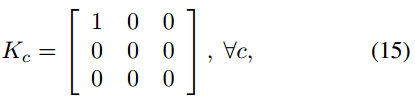
对应输出可以用公式表示成:
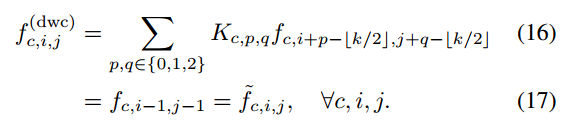
因此,通过为特定移位方向精心设计的核权值,卷积输出相当于简单张量移位(Eq.(14))。为了进一步融合不同方向特征的总和,我们将所有输入特征和卷积核分别连接起来,并将移位运算制定为单个群卷积,如图3 (c.I)所示。这种修改使我们的模块具有更高的计算效率。
在此基础上,我们还引入了一些适应性来增强模块的灵活性。如图3 (c.II)所示,我们将卷积核作为可学习权值释放,将移位核作为初始化。这在保持原有移位操作能力的同时,提高了模型容量。我们还使用多组卷积核来匹配卷积和自注意路径的输出通道维度,如图3 (c.III)所示。
4.4 Computational Cost of ACmix
为了便于比较,我们在表1中总结了ACmix的FLOPs和参数。第一阶段的计算成本和训练参数与自关注相同,并且比传统卷积(例如3×3 conv)更轻。在阶段II, ACmix引入了额外的计算开销,使用了一个轻的全连接层和第4.3节描述的群卷积,其计算复杂度与通道大小C呈线性关系,与阶段i相比相对较小。ResNet50模型中的实际成本与理论分析显示出类似的趋势。
4.5 Generalization to Other Attention Modes
随着自注意机制的发展,许多研究都集中在探索注意算子的变化,以进一步提高模型的性能。[54]提出的Patchwise attention将局部区域内所有特征的信息作为注意权值,取代了原有的softmax操作。Swing - Transformer[32]采用的窗口关注(Window attention)使token在同一局部窗口中保持相同的接受域,以节省计算成本,实现快速的推理速度。另一方面,ViT和DeiT[16,42]考虑了在单个层内保持长期依赖关系的全局关注。这些改进在特定的模型体系结构下被证明是有效的。
在这种情况下,值得注意的是,我们提出的ACmix独立于自关注公式,并且可以很容易地在上述变体上采用。具体来说,注意权重可以概括为:
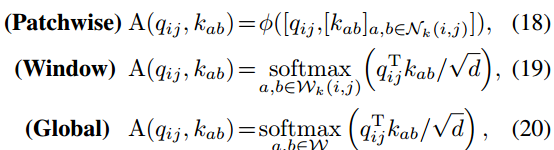
其中[·]为特征拼接,φ(·)表示两个具有中间非线性激活的线性投影层,Wk(i, j)为每个查询令牌的专门接受场,W表示整个特征图(详情请参考原文)。然后,计算出的注意力权重可应用于Eq.(12),并符合一般公式.
5. Experiments
在本节中,我们将在ImageNet分类、语义分割和对象检测任务上验证ACmix,并与最先进的模型进行比较。详细的数据集和训练配置见附录。
5.1 ImageNet Classification
实现。我们在4个基线模型上实际实现了ACmix,包括ResNet[20]、SAN[54]、PVT[44]和swing - transformer[32]。我们还将我们的模型与竞争基线进行了比较,即SASA[38]、LRNet[21]、aaa - resnet[3]、BoTNet[41]、T2T-ViT[52]、ConViT[12]、CVT[48]、ConT[51]和Conformer[36]。
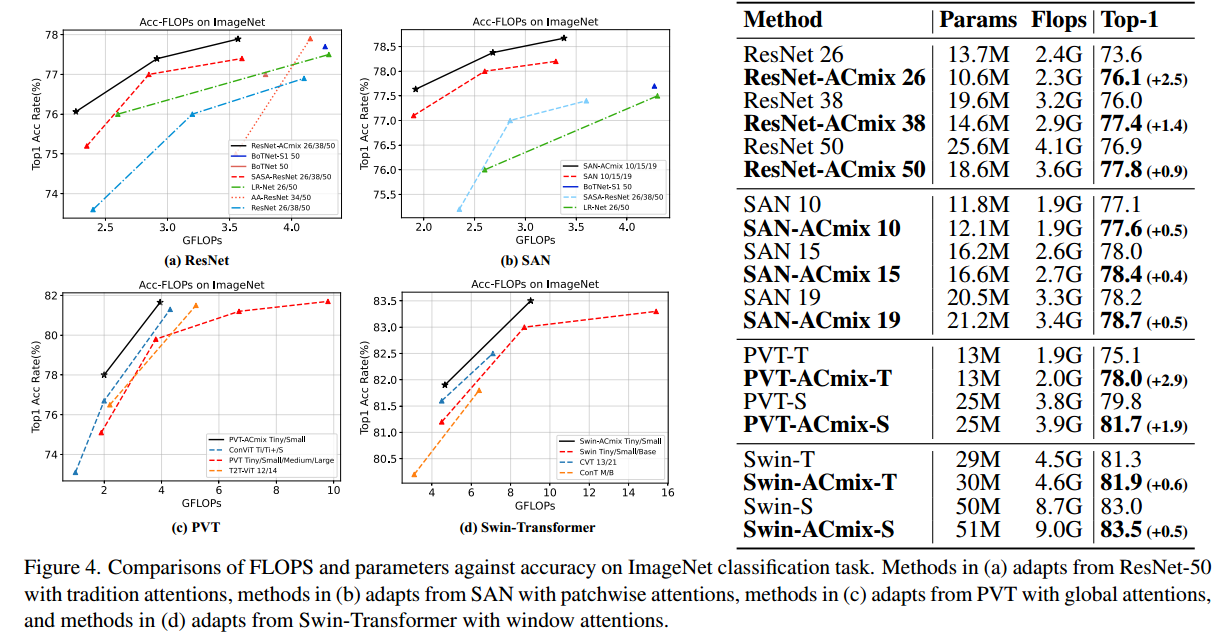
结果。分类结果如图4所示。对于ResNet-ACmix模型,我们的模型优于具有可比FLOPs或参数的所有基线。例如,ResNet-ACmix 26与SASA-ResNet 50的top-1精度相同,FLOPs为80%。在FLOPs相似的情况下,我们的模型比SASA高出0.35% - 0.8%。相对于其他基线的优势甚至更大。对于SANACmix、PVT-ACmix和swan - acmix,我们的模型实现了一致的改进。作为展示,SAN- acmix 15以80%的FLOPs优于SAN 19。PVT-ACmix-T表现出与PVT-Large相当的性能,只有40%的FLOPs。swan - acmix - s的精度比swan - b高,FLOPs为60%。
5.2 Downstream Tasks
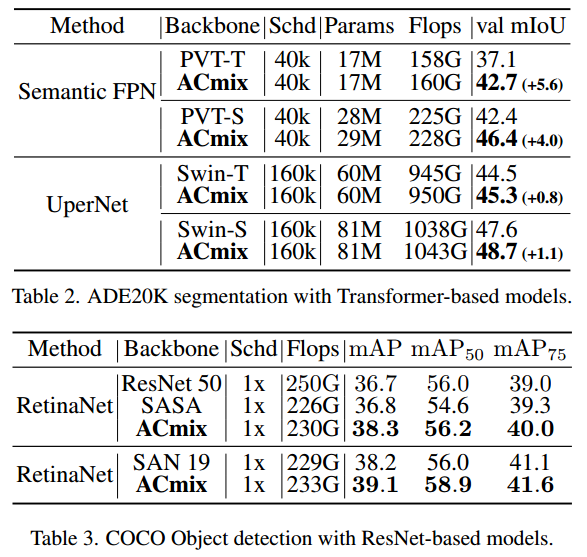
我们在一个具有挑战性的场景解析数据集ADE20K[56]上评估了我们的模型的有效性,并在Semantic- fpn[26]和UperNet[49]两种分割方法上展示了结果.
 .
.
在ImageNet-1K上对主干进行预训练。结果表明,在所有设置下,ACmix都实现了改进。
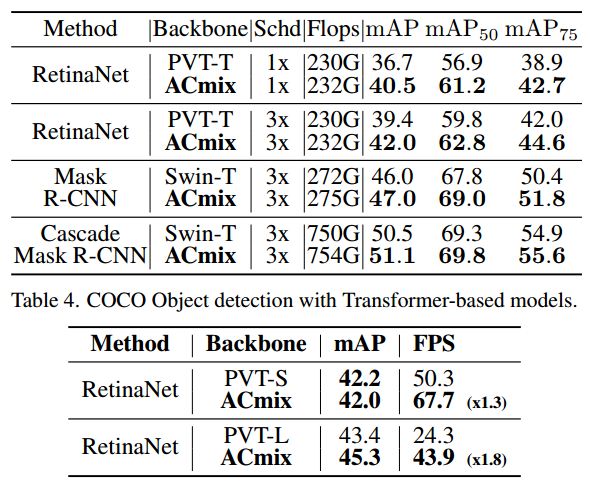
目标检测我们也在COCO基准上进行了实验[31]。表3和表4显示了基于resnet的模型和基于transformer的模型在不同检测头下的结果,包括retanet[30]、Mask R-CNN[19]和Cascade Mask R-CNN[5]。我们可以观察到,ACmix始终优于具有相似参数或FLOPs的基线。这进一步验证了ACmix在转移到下游任务时的有效性。
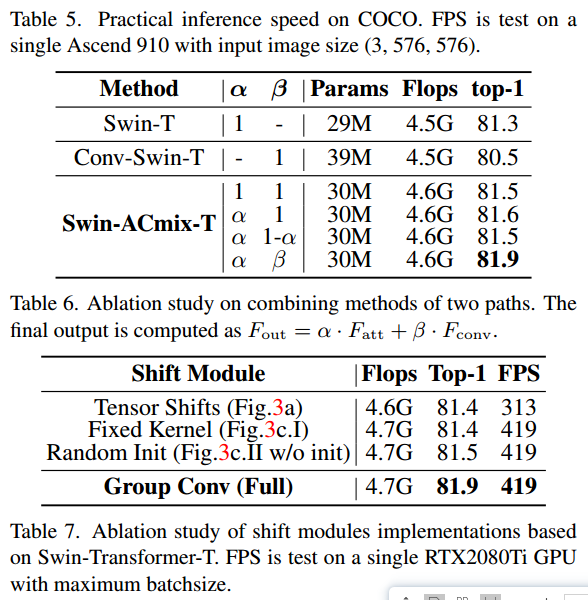
5.3 Practical Inference Speed
我们进一步研究了我们的方法在Ascend 910环境下的实际推理速度,MindSpore是一个用于移动、边缘和云场景的深度学习计算框架。我们将结果总结在表5中。与PVT-S相比,我们的模型在具有可比mAP的情况下实现了1.3倍的fps。当涉及到更大的模型时,优势更加明显。ACmix以1.8倍fps优于PVT-L 1.9mAP。
5.4 Ablation Study
为了评估ACmix中不同成分的有效性,我们进行了一系列的消融研究。
结合两条路径的输出。 我们探讨了卷积和自注意输出的不同组合如何影响模型的性能。我们采用多种组合方法进行实验,结果总结如表6所示。我们还展示了仅采用Swin-T作为自关注路径的模型的性能以及把窗口注意力机制替换成传统的3×3卷积后Conv-Swin-T。正如我们所观察到的,卷积和自关注模块的组合始终优于具有单一路径的模型。固定所有算子的卷积和自关注的比例也会导致性能变差。相比之下,使用学习参数为ACmix提供了更高的灵活性,并且可以根据滤波器在整个网络中的位置自适应调整卷积和自关注路径的强度。
组卷积核 我们还对组卷积核的选择进行了细化,正如我们在4.3节和图3中展示的,我们在表7中实证地展示了每种自适应的有效性及其对实际推理速度的影响。用群卷积代替张量位移,大大提高了推理速度。此外,使用可学习的卷积核和精心设计的初始化增强了模型的灵活性,并有助于最终的性能。
5.5 Bias towards Different Paths
同样有价值的是,ACmix引入了两个可学习的标量α, β来组合两条路径的输出(公式14)。这导致了我们模块的副产品,其中α和β实际上反映了模型在不同深度对卷积或自关注的偏见。
我们进行了并行实验从图5中SAN-ACmix和swan - acmix模型的不同层展示了可学习的参数。左图和中图分别显示了自注意率和卷积路径的变化趋势。在不同的实验中,速率的变化相对较小,特别是当层变深时。这一观察结果显示了对不同设计模式的深度模型的稳定偏好。右图显示了更明显的趋势,其中明确地表示了两条路径之间的比率。我们可以看到,在Transformer模型的早期阶段,卷积可以作为很好的特征提取器。在网络的中间阶段,模型倾向于利用两种路径的混合,并越来越偏向于卷积。在最后一个阶段,自注意力比卷积表现出优越性。这也与以往工作的设计模式一致,在最后阶段多采用自注意力来代替原有的3×3卷积[3,41],并且前期的卷积被证明对vision transformer更为有效[50]。
6. Conclusion
在本文中,我们探讨了卷积和自注意这两种强大的技术之间的密切关系。通过分解两个模块的操作,我们表明它们在投影输入特征映射时共享相同的计算开销。在此基础上,我们进一步提出了一种混合算子,通过共享相同的繁重操作来集成自关注和卷积模块。大量的图像分类和目标检测基准测试结果证明了该算子的有效性和效率。