
Abstract
在本文中,我们正式讨论了通用目标检测,其目的是检测每个场景并预测每个类别。对人工标注的依赖、有限的视觉信息以及开放世界中新出现的分类,严重制约了传统检测器的通用性。我们提出了UniDetector,一个通用的对象检测器,它有能力在开放世界中识别巨大的类别。UniDetector通用性的关键点是:
1)通过图像和文本空间的对齐,利用多源图像和异构标签空间进行训练,保证了足够的信息用于通用表示。
2)由于视觉和语言两种形态的丰富信息,它很容易泛化到开放世界,同时保持了可见和不可见类别之间的平衡。
3)通过我们提出的解耦训练方式和概率校准,进一步提升了对新类别的泛化能力。这些贡献使UniDetector能够检测超过7k个类别,这是迄今为止最大的可测量类别大小,只有大约500个类参与训练。我们的UniDetector在大型词汇数据集上表现出强大的零概率泛化能力——在没有看到任何相应图像的情况下,它比传统的基于监督的baseline平均高出4%以上。在13个具有各种场景的公共检测数据集上,UniDetector仅使用3%的训练数据就达到了最先进的性能。
1. Introduction
通用目标检测旨在检测每个场景中的所有事物。尽管现有的目标检测器已经取得了很大的成功,它们严重依赖于大规模的基准数据集[12,32]。然而,目标检测在类别和场景(即域)中是不同的。在开放世界中,由于与现有图像存在显著差异,并且出现了未见过的类,为了保证目标检测器的成功,必须重新重构数据集,这严重限制了其开放世界泛化能力。相比之下,即使是孩子在新环境中也能很快地进行概括。因此,普遍性成为人工智能与人类的主要差距。一旦经过训练,通用物体检测器可以直接在未知情况下工作,而无需进一步的重新训练,从而大大接近使目标检测系统像人类一样智能的目标。
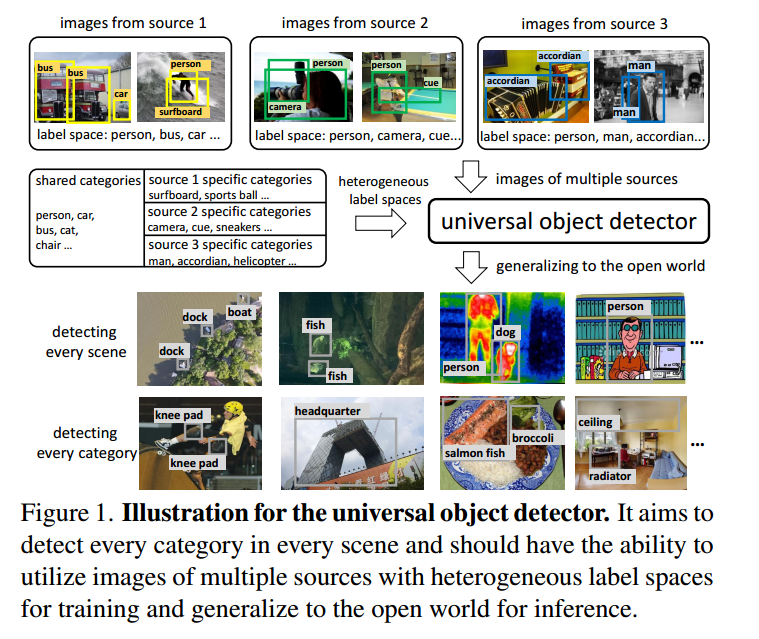
通用的目标检测器应该具备以下两种能力,首先它应该利用多种图像资源和用于训练的异构标签空间。为了保证检测器能够获得足够的泛化信息,需要在分类和定位方面进行大规模的协同训练。理想的大规模学习需要尽可能多地包含不同类型的图像,并使用高质量的边界框注释和大的类别词汇表。然而,受人类注释者的限制,这是无法实现的。在实践中,与小词汇表数据集[12,32]不同,大词汇表数据集[17,23]往往会有噪声标注,有时甚至会出现不一致的问题。相比之下,专门的数据集[8,55,70]只关注某些特定的类别。为了覆盖足够的类别和场景,检测器需要从以上所有图像中学习,从异构标签空间的多个来源中学习,这样才能学习到全面完整的知识,实现通用性。第二,它应该很好地推广到开放世界。特别是对于在训练过程中没有标注的新类,检测器仍然可以在不降低性能的情况下预测类别标签。
然而,纯粹的视觉信息并不能达到目的,因为完全的视觉学习需要人类的注释来进行全监督学习。
在本文中,我们正式解决了通用目标检测的任务。为了实现通用目标探测器的上述两种能力,需要解决两个相应的挑战。第一个是关于多源图像的训练。从不同来源收集的图像与异构标签空间相关联。现有的检测器只能从一个标签空间预测类,并且数据集之间特定于数据集的分类和注释不一致使得难以统一多个异构标签空间。第二部分是关于新类别歧视。受到最近图像-文本预训练的成功[20,39,58]的激励,我们利用他们的预训练模型和语言嵌入来识别未见的类别。然而,全监督训练使检测器专注于训练过程中出现的类别。在推理时,模型将偏向基类,并对新类产生不自信的预测。尽管语言嵌入使得预测新类成为可能,但它们的性能仍然远不如基本类别。
我们提出UniDetector,一个通用的目标检测框架,以解决上述两个问题。在语言空间的帮助下,我们首先研究了用异构标签空间训练检测器的可能结构,发现分割的结构促进了特征共享,同时避免了标签冲突。其次,为了利用区域提议阶段对新类别的泛化能力,我们将提议生成阶段和RoI分类阶段解耦,而不是将它们联合训练。这种训练模式很好地利用了他们的特点并且有利于检测器的通用性。在解耦方式下,我们进一步提出了一种用于生成广义区域建议的类不可知定位网络(CLN)。最后,我们提出了概率校准来消除预测偏差。我们估计所有类别的先验概率,然后根据先验概率调整预测的类别分布。校正后的新类的性能得到了很好的改善。
我们的主要贡献可以概括如下:
•我们提出了UniDetector,这是一个通用的检测框架,使我们能够利用异构标签空间的图像并推广到开放世界。据我们所知,这是第一个正式解决普遍目标检测的工作。
•考虑到新类别识别泛化能力的差异,我们提出将proposal generation和RoI分类的训练解耦,以充分挖掘类别敏感特征。
•我们建议校准生成的概率,这平衡了预测的类别分布,并提高了新类别的自信心。
大量的实验证明了UniDetector具有很强的通用性。它识别最可衡量的类别。在没有看到任何来自训练集的图像的情况下,我们的UniDetector在现有的大型词汇数据集上实现了比完全监督方法高4%的AP。除了开放世界任务之外,我们的UniDetector在封闭世界中也取得了最先进的结果-使用纯CNN模型,ResNet50和1x调度,在COCO上实现了49.3%的AP。
2. Related Work
目标检测 目的是预测图像中每个对象的类别标签和边界框坐标。现有的方法一般可分为两阶段法和一阶段法。两级检测器主要包括RCNN[15]及其变体[4,14,18,43]。它们通常首先提取一系列区域建议,然后进行分类和回归。相比之下,一级检测器[31,33,42]直接对锚点产生分类结果。与这些方法不同的是,[26,50,61,67]等模型不需要锚点来检测目标。近年来,基于transformer的方法[5,10,27,60,71]也发展迅速。然而,这些方法中的大多数只能在封闭的世界中工作。
开放词汇目标检测 传统的目标检测只能检测在训练时出现的类别。在通用对象检测中,需要检测的类别是无法提前知道的。为此,提出了零射击目标检测[1,40,68,69],旨在从可见类别推广到未见类别。然而,它们的性能仍然远远落后于完全监督的方法。基于这些研究,开放词汇目标检测[57]将任务转发。通过包含图像文本对齐的训练,文本中的无界词汇有利于模型在检测新类别时的泛化能力。随着大规模图像-文本预训练工作的发展[20,39,58],最近的方法[11,13,16,37,63]已经考虑在开放词汇检测中采用这种预训练参数,并在很大程度上提高了性能和类别词汇。尽管它们取得了成功,但现有的方法仍然针对单个数据集内的传输。此外,他们看到的类别通常比看不见的类别多。他们的泛化能力因此受到限制。
多数据集目标检测训练。以前的目标检测方法只关注单个数据集。由于训练只涉及一个数据集,因此数据集规模和词汇量都是有限的。最近,在多个数据集上进行训练[3,46]已被用于提高模型的鲁棒性并扩大检测器的词汇量。多数据集训练目标检测的难点在于如何利用多个异构标签空间。为此,[62]利用伪标签统一不同的标签空间,[53,66]采用分区结构,[36]利用语言嵌入。然而,这些方法仍然侧重于封闭世界的检测。与他们不同的是,我们的目标是在开放世界中进行泛化。
3. Preliminary
给定图像I,目标检测的目的是预测其标签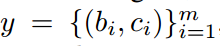 ,该标签由边界框坐标bi和类别标签ci组成。我们通常给出一个单一的数据集
,该标签由边界框坐标bi和类别标签ci组成。我们通常给出一个单一的数据集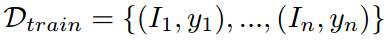 ,目标是在测试数据集Dtest上进行推理。
,目标是在测试数据集Dtest上进行推理。
传统的目标检测只能在封闭的世界中工作,其中图像被限制在单个数据集中。数据集有自己的标签空间l,来自Dtrain或者Dtest的每个对象类别ci属于相同的预定义标签空间(即类词汇表)L。
在这项工作中,我们提出了一个全新的目标检测任务,其重点是检测器的通用性。在训练时,我们利用来自多个来源的图像。即异构标签空间L1, L2,…Ln的图像。在推理时,检测器从用户提供的新标签空间Ltest中预测类标签。
传统目标检测技术的进步不能轻易适应我们的通用检测任务。主要原因是在推理时存在新颖的范畴: 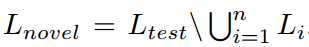 。传统的目标检测技术有利于基础类别
。传统的目标检测技术有利于基础类别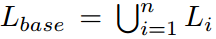 ,但可能会损害新的类别。因此,我们工作的核心问题是如何利用异质标签空间的图像,以及如何推广到新的类别。
,但可能会损害新的类别。因此,我们工作的核心问题是如何利用异质标签空间的图像,以及如何推广到新的类别。
4. The UniDetector Framework
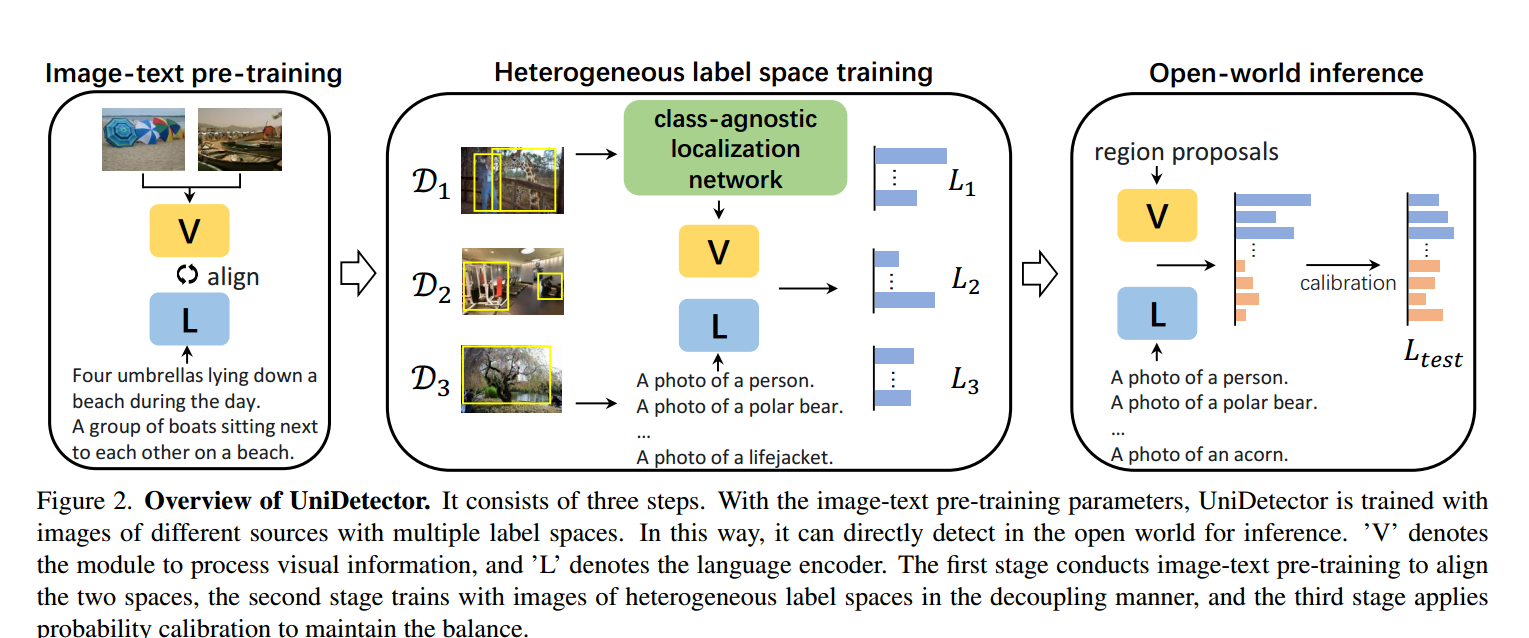
我们提出了UniDetector框架来解决通用对象检测任务,如图2所示。基本过程包括三个步骤。
Step1:大规模图像-文本对齐预训练。传统的视觉信息全监督学习依赖于人工标注,限制了学习的通用性。考虑到语言特征的泛化能力,我们引入语言嵌入来辅助检测。受最近语言-图像预训练成功的启发,我们采用了预训练图像-文本模型的嵌入[20,39,58,63]。我们采用RegionCLIP[63]预训练参数进行实验。
Step2:异构标签空间训练. 传统的目标检测集中在具有相同标签空间的单个数据集上,与之不同的是,我们从具有异构标签空间的不同来源收集图像来训练检测器。各种各样的训练图像对检测器的通用性是必要的。同时,我们在训练过程中采用了解耦的方式,而不是以前的联合训练。
Step3:开放世界推理。使用训练好的对象检测器和来自测试词汇表的语言嵌入,我们可以直接在开放世界中执行检测以进行推理,而无需进行任何微调。然而,由于在训练过程中没有出现新的类别,检测器很容易产生不自信的预测。在这一步中,我们提出了概率校准来保持基本类别和新类别之间的推理平衡。
4.1. 异构标签空间训练
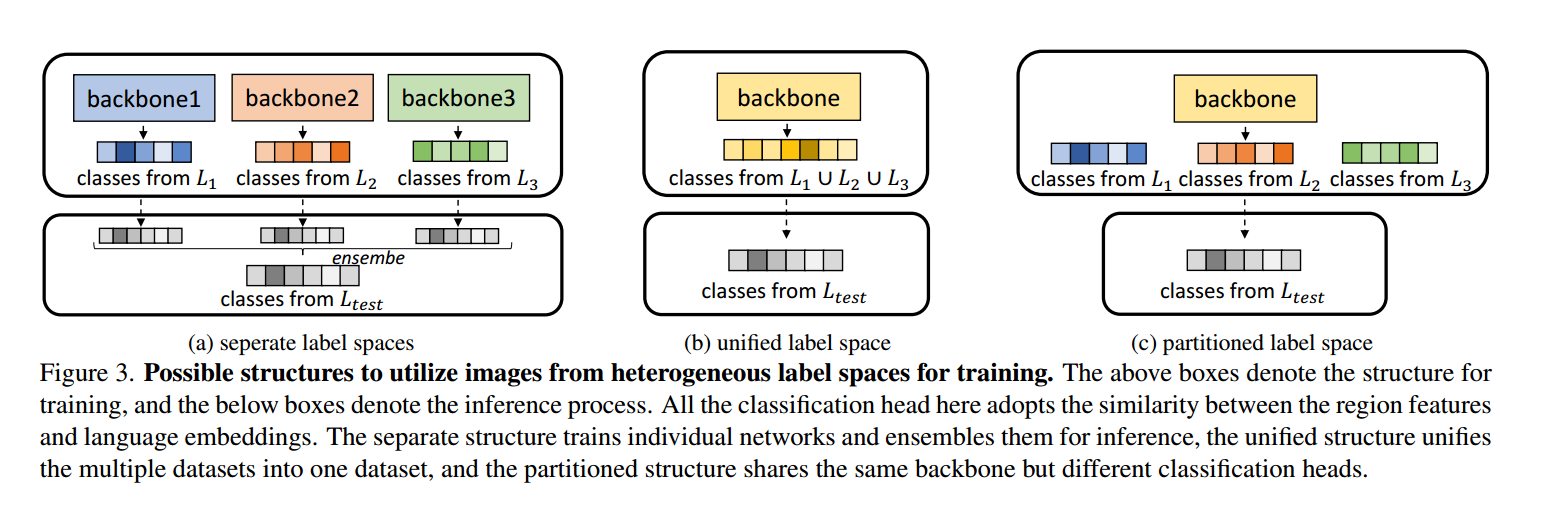
现有的目标检测器由于分类层单一,只能从单一标签空间的图像中学习。为了使用异构标签空间进行训练并获得足够多样化的普适性信息,我们提出了三种可能的模型结构,如图3所示。
一种可能的结构是使用单独的标签空间进行训练。如图3a所示,我们在每个数据集(即标签空间)上训练多个模型。通过在推理时嵌入新的语言,每个模型都可以对测试数据进行推理。这些单独的测试结果可以结合起来得到最终的检测箱。另一种结构是将多个标签空间统一为一个标签空间,如图3b所示。然后我们可以像以前一样处理这些数据。由于图像被视为来自单个数据集,因此可以使用Mosaic[2]或Mixup[59]等技术来处理图像,以增强不同标签空间之间的信息集成。借助语言嵌入进行分类,我们还可以使用图3c所示的分割结构,其中多个源图像共享相同的特征提取器,但具有各自的分类层。在推理时,我们可以直接使用测试标签的类嵌入来避免标签冲突。
然后我们需要考虑数据采样器和损失函数。当数据变成大规模时,一个不可避免的问题是它们的长尾分布[23,25,45]。类感知采样器(class-aware sampler, CAS)[38]和重复因子采样器(repeat factor sampler, RFS)[17]等采样器是封闭世界中多数据集检测的有用策略[66]。然而,开放世界的性能不受影响。原因是这里的核心问题是关于新颖的课程。对于语言嵌入,长尾问题的不利影响可以忽略不计。因此,我们采用随机抽样方法。
同样,均衡损失[48,49]和跷跷板损失[52]等损失函数对通用目标检测影响较小。
而基于sigmoid的损失更合适,因为在sigmoid函数下,基本类别和新类别的分类不会相互干扰。为了避免当类别数量增加时基于s型的分类损失值过大,我们随机抽取一定数量的类别作为负类别。
解耦提案生成和RoI分类。两级目标检测器由视觉主干编码器、RPN和RoI分类模块组成。给定图像I,数据集D和标注空间L,任务可以概括为:
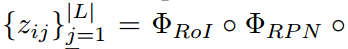
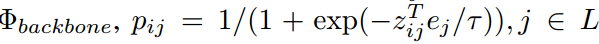
其中pij是第i个区域对应类别j的概率是多少,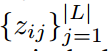 表示RoI头部的logit输出,ej是类别j的语言嵌入。
表示RoI头部的logit输出,ej是类别j的语言嵌入。
当涉及到通用检测时,区域建议生成阶段和RoI分类阶段的行为是不同的。提案生成阶段由于其类别不可知论分类可以很容易地扩展到新的类别,因此保持了良好的通用性。相比之下,特定于类别的RoI分类阶段甚至不能用于新类别。即使使用语言嵌入,它仍然偏向于基类。由于分类阶段对新类别的敏感性阻碍了提案生成阶段的通用性,不同的属性影响了它们的联合训练。因此,我们将这两个阶段解耦并分别训练它们以避免此类冲突。
具体而言,区域建议生成阶段使用传统ImageNet预训练参数初始化并以一种阶级不可知论的方式接受训练。经过训练,生成一系列区域建议。使用生成的提案,以Fast RCNN[14]的方式训练RoI分类阶段。这个阶段用imagetext预训练参数初始化,用于预测未见过的类别。这两种预训练参数还包含互补特征,为通用目标检测提供了更全面的信息。
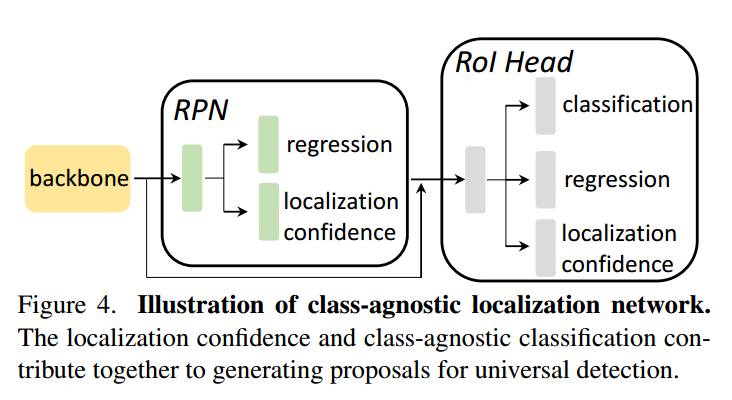
与类别无关的定位网络。为了在开放世界中提出一般化的建议,我们提出了分类无关定位网络(CLN),如图4所示。我们的CLN不是单个RPN模块,而是包含RPN和RoI头,以生成通用对象检测的建议。这种网络促进了提案生成过程中的盒子细化。我们主要采用基于定位的对象来发现对象,因为与定位相关的度量往往对开放世界中的新对象具有鲁棒性[21]。在RoI头部,基于定位置信度,我们还保留了二元分类,因为它为网络训练提供了强监督信号。对于第i个提议,表示其从RPN得到的定位置信度为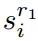 ,来自RoI头部表示为:
,来自RoI头部表示为: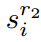 , ,其分类置信度为sci,则CLN的最终置信度可通过几何加权得到:
, ,其分类置信度为sci,则CLN的最终置信度可通过几何加权得到:
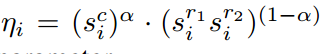 其中α是一个预定义的超参数。
其中α是一个预定义的超参数。
4.2 Open-world inference
通过测试词汇Ltest的语言嵌入,我们训练好的检测器可以直接在开放世界中进行推理。然而,由于在训练过程中只出现基本类别,训练后的检测器将偏向于基本类别。因此,检测结果中基本类别的方框往往比新类别具有更大的置信度得分,从而在推理过程中占主导地位。考虑到大量的新类别,基类的过度置信度很容易使检测器忽略更多数量的新类别实例,从而影响检测器在开放世界中的性能。
为了避免偏差问题,我们提出了对预测进行后处理的概率校准。校准的目的是降低基本类别的概率,增加新类别的概率,从而平衡最终概率预测。概率校准示意图如下:
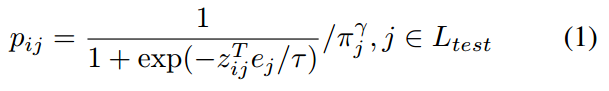
我们的概率标定主要是将原始概率除以类别j的先验概率πj。先验概率πj记录了网络对类别j的偏差。γ是一个预定义的超参数。
πj越大,表明模型更偏向于该类别。校正后,其概率变小,有利于概率平衡。我们可以先对试验数据进行推断,利用结果内的类别数得到πj。如果测试图像的数量太少,无法估计准确的先验概率,我们也可以使用训练图像来计算πj。
Eq. 1中的pij反映了第i个区域提案的类别特定预测。考虑到类不可知性任务的开放世界泛化能力,我们将pij与CLN中的对象分数ηi相乘作为检测分数。在进一步引入超参数β后,最终的检测分数为:
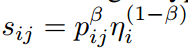
5. Experiments
为了证明我们的UniDetector的通用性,我们在开放世界、传统封闭世界和野外进行了实验和评估。它在各种条件下的优越性能很好地说明了它的普遍性。
Datasets 为了模拟多源和异构标签空间的图像,我们采用了三种流行的目标检测数据集来训练检测器:COCO[32]、Objects365[45]和OpenImages[25]。COCO包含来自80个常见类的密集和高质量的人工注释。Objects365规模更大,包含365个类。OpenImages由更多的图像和500个类别组成,许多注释是稀疏和肮脏的。由于这些数据集的规模很大,我们分别从中随机抽取35k、60k和78k图像进行训练。在没有说明的情况下,我们都使用选定的子集。
我们主要对LVIS[17]、ImageNetBoxes[24]和VisualGenome[23]数据集进行推理,以评估检测器的开放世界性能。考虑到它们的大类别数量,这些数据集可以在一定程度上模拟开放世界环境。LVIS v0.5包含1,230个类别,LVIS v1包含1,203个类别,验证集分别包含5,000张图像和19,809张图像。ImageNetBoxes包含超过3000个类别。我们从数据集中随机抽取20000张图像进行评估。为了和有监督的封闭世界baseline比较,我们抽取9万张图片作为训练集。最新版本的VisualGenome数据集包含7605个类别。然而,由于它的大量注释来自机器,因此注释非常嘈杂。我们选择5000张没有出现在训练图像中的图像进行推理。
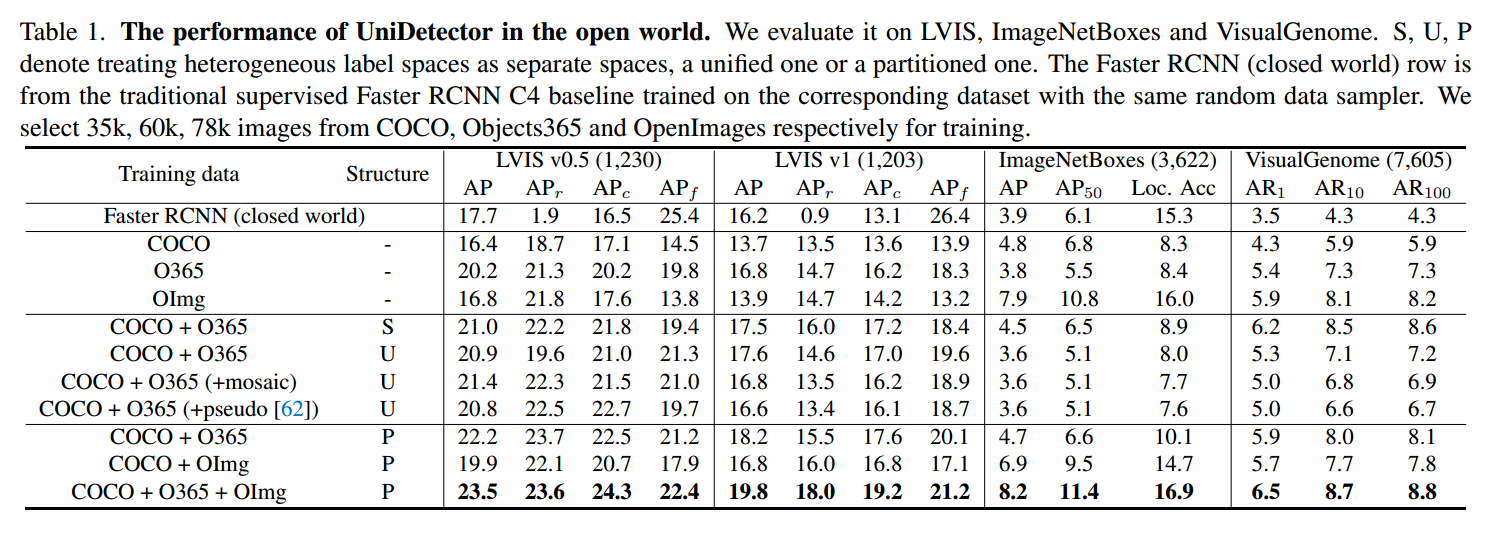
评价指标。我们主要采用标准box AP来评估性能。对于LVIS数据集,我们还分别评估了其罕见、常见和频繁类别的性能,分别表示为APr、APc和APf。对于ImageNetBoxes数据集,由于其中的大多数图像都是以对象为中心的,除了AP和AP50指标外,我们还采用了top-1的定位精度(表示为Loc。Acc.),从ImageNet挑战[44]中评估检测器的以对象为中心的分类能力。对于VisualGenome数据集,考虑到其注释的噪声和不一致性,我们采用平均召回率(AR)指标进行评估。
实施细节 我们使用mmdetection来实现我们的方法[7]。在没有特别说明的情况下,我们选择基于ResNet50-C4[19]的Faster RCNN[43]作为检测器,使用RegionCLIP[63]预训练参数进行初始化。所有的模型都按照1x时间表进行训练,即12个epoch。对于超参数,τ设为0.01,γ设为0.6,α、β均设为0.3.
5.1 Object Detection in the Open World
我们在表1中列出了UniDetector的开放世界结果。为了比较,我们使用相同的Faster RCNN C4结构和随机数据采样器进行了有监督的封闭世界实验。在LVIS v0.5数据集上,传统的监督检测器获得17.7%的AP。相比之下,我们的UniDetector只有35k张COCO图像,获得16.4%的AP。只有60k张Objects365图像,它获得20.2%的AP。随着图像和注释类别的显著减少,检测AP甚至更高。我们的UniDetector的有效性证明: 它能够实现相媲美的甚至更优越的性能和对应的封闭世界检测器比较而言。而所需的训练成本更少。另一个值得注意的结果是,传统的封闭世界检测器存在长尾问题——APr仅为1.9%,而APf为25.4%。相比之下,我们的检测器的APr和APf明显更加平衡。这说明UniDetector也极大地缓解了长尾效应。
然后,我们分析了不同结构对COCO和Objects365数据集的影响。我们使用WBF[47]对两个独立标签空间的检测器进行集成。在这种结构下,不同来源的图像在训练过程中无法相互作用,从而限制了特征提取的能力。对于统一空间,不同数据集的标签不一致导致了严重的缺失标注问题。虽然我们根据[62]采用伪标签,并通过拼接增强图像融合,但开放世界AP仍然没有得到改善。相反,在分割结构下,各种图像一起训练主干,从而促进特征提取。在分类时间内,通过划分标签空间,可以缓解标签冲突。因此,分区结构是其中性能最好的。
在分割结构下,COCO和Objects365联合训练的AP达到22.2%,高于单独训练的16.4%和20.2%。我们还注意到,OpenImages单次训练获得了16.8%的LVIS AP,仅略高于COCO,甚至低于Objects365。考虑到其中的图像和类别较多,其性能有限可以归因于其嘈杂的注释。但是,如果我们进一步向COCO和Objects365添加OpenImages图像,则LVIS v0.5 AP可以提高到23.5%。此时,COCO和Objects365图像具有高质量的注释,而OpenImages提供了更多的类别,但是有噪声的注释。来自多个来源的图像相互协作,带来不同的信息,从而有助于更好的开放世界性能。这是用异步标签空间来统一目标检测训练最突出的优越性。在LVIS v1中也观察到类似的结果趋势。
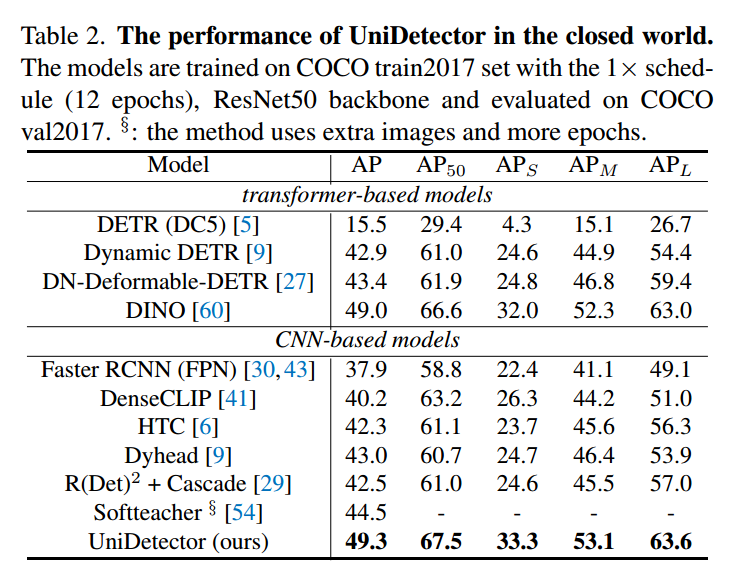
我们在ImageNetBoxes和VisualGenome数据集上进一步评估我们UniDetector。这两个数据集包含更多的类别,从而更好地模拟开放世界环境。我们的UniDetector保持了优秀的开放世界泛化能力。在ImageNetBoxes数据集上,它获得了8.2%的AP,超过了具有可比训练图像的传统检测器的3.9% AP。同样值得一提的是,ImageNetBoxes数据集和coco风格的数据集之间的领域差距相对较大,因为ImageNetBoxes图像主要是以对象为中心的。在这种情况下,我们的UniDetector仍然泛化得很好,这验证了我们的UniDetector的通用性。在超过7000个类别的VisualGenome数据集上,我们的UniDetector也获得了比传统Faster RCNN更高的检测结果。最显著的改进来自AR100指标,提高了4%以上。通过这个实验,揭示了我们的UniDetector的分类识别能力。
5.2 Object Detection in the Closed World
一个通用的目标检测模型既要对开放世界有很好的泛化能力,又要保持在封闭世界中的优势,这在训练中已经体现出来。因此,我们只使用COCO训练集中的图像来训练我们的UniDetector,并在COCO 2017验证集中对其进行评估。我们将我们的结果与现有最先进的封闭世界检测模型进行了比较,并在表2中给出了检测AP。在本小节中,我们使用R(Det)2[29]和级联结构[4]作为检测器。对于我们的CLN,我们引入Dyhead[9]结构和focal loss[31]进行分类。采用AdamW[22,34]优化器,初始学习率为0.00002。
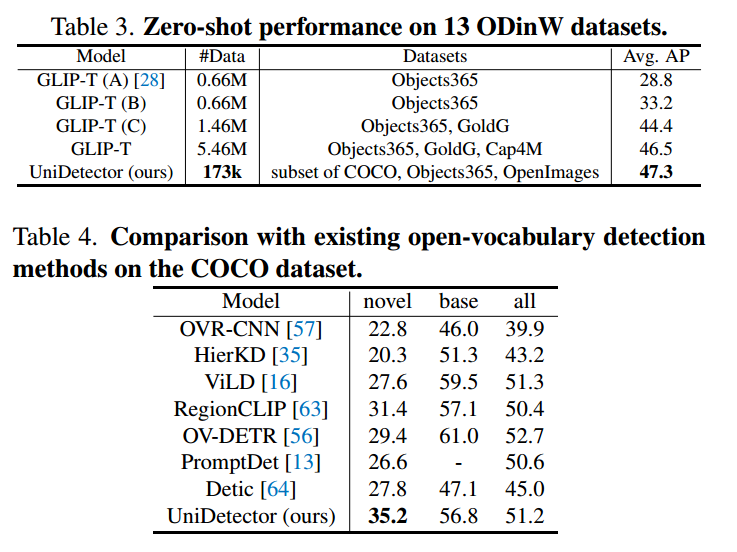
使用ResNet50作为backbone和1x结构,我们的UniDetector用纯CNN结构取得了49.3%AP,我们比最先进的CNN检测器Dyhead[9]高出6.3%的AP。与Softteacher54相比,我们的UniDetector也实现了4.8%的AP。与最近基于变压器的检测器相比,性能优势也很明显。结果表明,我们的UniDetector不仅在开放世界中泛化得很好,在封闭世界中也很有效。开放世界和封闭世界的优越性,有力地证实了我们的UniDetector的普适性。
5.3 Object Detection in the Wild
为了进一步证明我们的UniDetector能够检测每个场景中的一切,我们按照[28]在13个ODinW数据集上进行了实验。这些数据集涵盖了不同的领域,如无人机,水下,热,因此也具有多样性的类别。这种性质使它适合于测量探测器的通用性。我们在表3中列出了这13个数据集的平均AP。与GLIP-T相比,其主干(swan - tiny)比我们的(ResNet50)需要更多的预算,我们的方法实现了更高的平均AP (47.3% vs . 46.5%)。
相比之下,我们的方法只利用了GLIP-T数据量的3%。该实验验证了UniDetector的通用性,并说明了其出色的数据效率.
5.4 Comparison with Open-vocabulary Methods
为了与现有的开放词汇表工作进行公平的比较,我们对现有的开放词汇表工作进行了实验,以进一步展示我们的UniDetector的有效性,具体来说,COCO数据集和LVIS v1数据集分别以48/17和866/337的方式对基础类和新类进行了拆分。对于LVIS实验,我们采用与Detic[64]和Dyhead[9]相同的CenterNet2[65]结构和图像级注释图像进行检测学习,Dyhead[9]进行提议生成。表4和表5列出了新类和基类上的框AP和掩码AP。
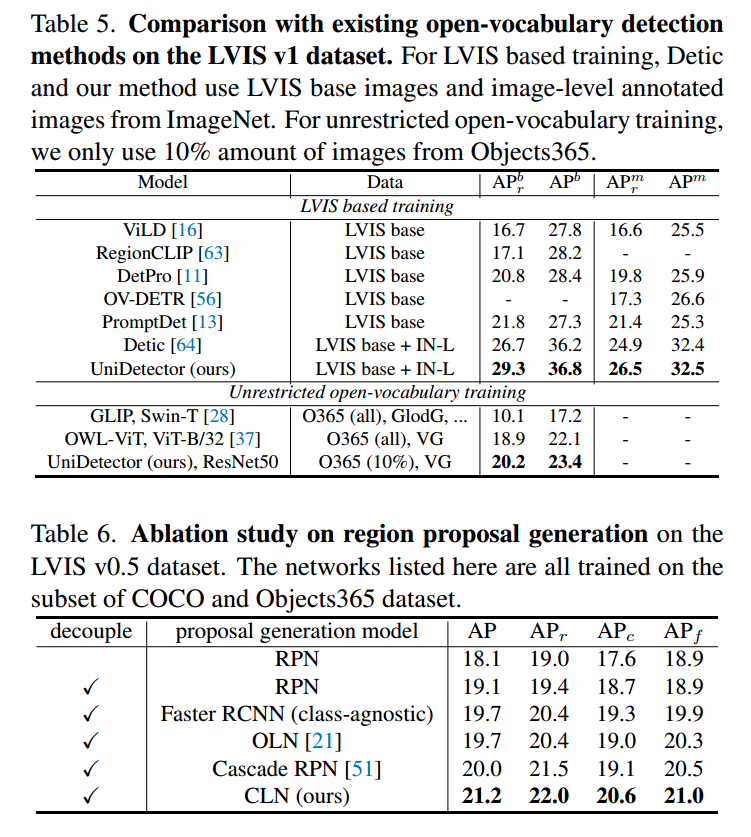
得到的方框AP有力地证明了我们的UniDetector对新类的泛化能力。在COCO数据集上,我们获得了新类的35.2%的box AP,比之前最好的方法(来自RegionCLIP的31.7%)高出3.5%。在LVIS数据集上,我们获得了新类别的29.3%框AP和26.5%掩码AP(即本例中的APr),分别比Detic高2.6%和1.6%。对新类别的显著改进验证了我们的方法对未见过的类的出色能力。值得一提的是,在这个实验设置中只涉及一个检测数据集,其中我们的UniDetector甚至受到单一图像来源的限制。当引入多个数据集进行训练时,我们的方法的优越性更加突出。仅使用10%的训练图像,我们就比OWL-ViT多了1.3%的新类别。这一比较很好地说明了其普遍性。
5.5 Ablation Study
最后,我们在本节进行消融研究。本文主要分析了解耦区域建议生成和概率校准的效果。
解耦提案生成和RoI分类。表6分析了解耦训练方式的效果。在COCO和Objects365上训练的一个简单的Faster RCNN在LVIS上获得了18.1%的开放世界AP。如果我们将这两个阶段解耦,则盒AP为19.1%。1.0%AP的提高表明了解耦的方式对于开放世界检测更加有利,而这在传统的封闭世界检测中不会发生。如果我们用类不可知性的Faster RCNN提取区域建议,AP为19.7%。0.6%的改进表明,具有RPN和RoI头部的结构比单个RPN更适合在开放世界中生成提案。如果我们采用同样带有RoI头部的OLN [21], LVIS AP仍然是19.7%,这表明单纯的定位信息并不能带来进一步的改善。我们的CLN具有分类得分和定位质量,贡献了21.2%的AP。这个AP不仅高于类似预算的网络,也高于更复杂的模型,如Cascade RPN。这证明了解耦学习方式和我们的CLN的有效性。
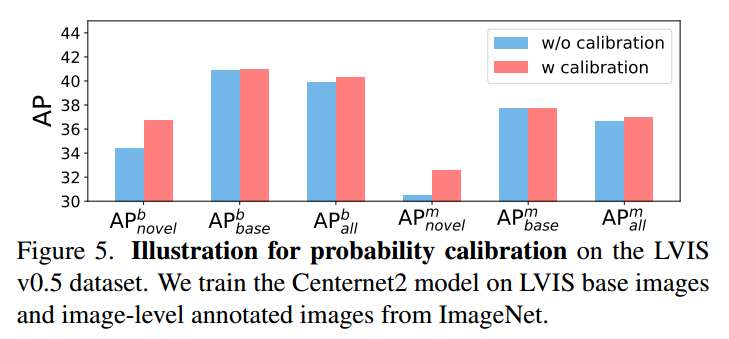
概率校准 我们进一步分别测量新类别和基本类别的AP,以检验概率校准的能力。我们遵循Detic[64]在LVIS v0.5上的设置,并在图5中绘制框和掩码AP。我们注意到,在校正后,新类别的盒形AP和遮罩AP均有显著提高,均超过2%。因此,基类和新类之间的性能差距显著减小。相比之下,基类的性能几乎保持不变。这是因为我们设计的先验概率大大降低了基本类别的自信心。正如我们所看到的,概率校准减轻了训练模型的偏差,从而有助于在开放世界中生成更平衡的预测。
6.Conclusion
本文提出了一种通用的目标检测框架UniDetector。通过利用多源图像,异构标签空间,并将检测器推广到开放世界,我们的UniDetector可以直接检测每个场景中的所有内容,而无需任何微调。在大词汇量数据集和不同场景上的大量实验证明了其强大的通用性——它表现出迄今为止识别大多数类别的能力。普遍性是一个至关重要的问题,它弥合了人工智能系统和生物机制之间的差距。我们相信我们的研究将在未来激发沿着通用计算机视觉方向的后续研究。