
抽象卷积网络不知道对象的几何变化,这导致模型和数据容量的低效利用。 为了克服这个问题,最近关于变形建模的工作试图在空间上将数据重新配置为一个共同的排列,以便语义识别受到变形的影响较小。 这通常是通过在图像空间中使用学习的自由形式采样网格增加静态算子来完成的,动态调整到数据和任务以适应感受野。 然而,调整感受野并不能完全达到实际目标——对网络来说真正重要的是有效感受野 (ERF),它反映了每个像素的贡献程度。 因此,设计其他方法在运行时直接调整 ERF 是很自然的。
在这项工作中,我们将一种可能的解决方案实例化为可变形内核 (DK),这是一系列新颖的通用卷积算子,用于通过直接调整 ERF 来处理对象变形,同时保持感受野不变。 我们方法的核心是能够重新采样原始内核空间以恢复对象的变形。 这种方法在理论上是合理的,即 ERF 严格由数据采样位置和内核值决定。 我们将 DK 实现为刚性内核的通用替代品,并进行了一系列实证研究,其结果符合我们的理论。在多个任务和标准基础模型中,我们的方法与在运行时适应的先前工作相比具有优势。 此外,进一步的实验表明了一种与以前的工作正交和互补的工作机制
1. 介绍
图像中对象外观的丰富多样性源于对象语义和变形的变化。 语义描述了我们感知的高级抽象,而变形定义了与特定数据相关的几何变换(Gibson,1950)。 人类非常擅长抽象世界(Hudson & Manning,2019); 我们在原始视觉信号、远离变形的抽象语义和形式概念中看到。
有趣的是,现代卷积网络遵循类似的过程,通过局部连接和权重共享进行抽象(Zhang,2019)。 然而,这种机制是一种低效的机制,因为紧急表示将语义和变形编码在一起,而不是作为不相交的概念。 尽管卷积会相应地响应每个输入,但它的响应方式主要由其刚性内核所决定,如图 1(a,b)所示。 实际上,这会消耗大量模型容量和数据模式(Shelhamer 等人,2019 年)。
我们认为,变形意识来自适应性——运行时的适应能力(Kanazawa et al., 2016; Jia et al., 2016; Li et al., 2019)。 几十年来,几何变换建模一直是视觉研究人员不断追求的目标(Lowe 等人,1999;Lazebnik 等人,2006;Jaderberg 等人,2015;Dai 等人2017)。 一个基本思想是在空间上将数据重组为一个共同的模式,这样语义识别就不会受到变形的影响。 最近的一项工作是这个方向的代表是可变形卷积(Dai et al., 2017; Zhu et al., 2019)。 如图 1(c) 所示,它在数据空间中使用自由形式的采样网格来增强卷积。它以前被认为是适应感受野,或者我们所说的“理论感受野”,它定义了哪些输入像素可以对最终输出做出贡献。 然而,理论上的感受野并不能衡量输入像素的实际影响有多大。 另一方面,罗等人。(2016)提出测量有效感受野(ERF),即输出相对于输入数据的偏导数,以量化每个原始像素对卷积的确切贡献。 既然调整理论感受野不是目标,而是调整 ERF 的一种手段,为什么不在运行时直接调整 ERF 以适应特定数据和任务呢?
为此,我们引入了可变形内核 (DK),这是一组用于变形建模的新颖通用卷积算子。 我们的目标是增强刚性内核的表达能力,以便在推理过程中直接与计算的 ERF 交互。 如图 1(d) 所示,DK 学习内核坐标上的自由形式偏移,以将原始内核空间变形为特定的数据模态,而不是重新组合数据。 这可以直接适应 ERF,同时保持感受野不变。 与数据坐标无关的 DK 设计自然会导致两种变体——全局 DK 和局部 DK,正如我们稍后研究的那样,它们在实践中的行为不同。我们用理论结果证明我们的方法是正确的,理论结果表明 ERF 严格由数据采样位置和内核值决定。 作为刚性内核的通用替代品,DK 实现了与我们开发的理论相一致的经验结果。 具体来说,我们使用图像分类和对象检测的标准基础模型来评估我们的算子。 与在运行时适应的先前工作相比,DK 表现良好。 通过定量和定性分析,我们进一步表明 DK 可以与以前的技术正交和互补地工作。
2. 相关工作
我们在变形建模作为我们的目标和动态推理作为我们的手段的背景下区分我们的工作。
变形建模:我们将变形建模称为在 2D 图像空间中学习几何变换,而不考虑 3D。 攻击变形建模的一个角度是将某些几何不变性制作成网络。 然而,这通常需要针对特定类型的变形进行设计,例如移位、旋转、反射和缩放(Sifre & Mallat, 2013; Bruna & Mallat, 2013; Kanazawa et al., 2016; Cohen & Welling, 2016; Worrall et 等人,2017 年;Esteves 等人,2018 年)。 该主题的另一项工作是通过图像空间中的半参数化或完全自由形式的采样来学习重构数据:Spatial Transformers (Jaderberg et al., 2015) learning 2D affine transformations, Deep Geometric Matchers (Rocco et al., 2017)学习薄板样条变换,可变形卷积(Dai et al., 2017; Zhu et al., 2019)学习自由形式的变换。
我们将采样数据空间解释为通过直接改变感受野来适应有效感受野(ERF)的有效方法。 在高层次上,我们的可变形内核 (DK) 与这一系列工作共享直觉,用于学习几何变换,但通过学习在内核空间中采样来实例化,直接适应 ERF,同时保持理论接受域不变。
虽然 Deformable Filter (Xiong et al., 2019) 和 KPConv (Thomas et al., 2019) 中也研究了内核空间采样,但在它们的上下文中,采样网格是从输入点云计算的,而不是从数据语料库中学习的。
动态推理:动态推理使模型或单个操作适应观察到的数据。 我们的方法的计算不同于自我注意(Vaswani 等人,2017 年;Wang 等人,2018 年),其中线性或卷积模块通过从相同输入中提取的后续查询来增强。 我们认为我们在实现方面最接近的相关工作是那些在运行时适应卷积核的方法。 它包括但不限于动态过滤器 (Jia et al., 2016)、选择性内核 (Li et al., 2019) 和条件卷积 (Yang et al., 2019)。 所有这些方法都可以学习和推断与数据相关的定制内核空间,但要么效率低下,要么公式松散。 动态过滤器从头开始生成新的过滤器,而条件卷积将这个想法扩展到一组合成过滤器的线性组合。 另一方面,选择性内核相对来说是轻量级的,但是从不同大小的内核聚合激活不如直接采样原始内核空间那么紧凑。 与我们同时代的另一系列作品(Shelhamer 等人,2019 年;Wang 等人,2019 年)是用结构化的高斯滤波器组合自由形式的滤波器,它本质上是通过数据转换内核空间。 我们的 DK 也与这些作品不同,强调直接适应 ERF 而不是理论接受域。 如前所述,真正的目标应该是适应 ERF,据我们所知,我们的工作是第一个研究 ERF 的动态推理的工作。
3. 方法
我们首先介绍卷积的初步知识,包括有效感受野 (ERF) 的定义。 然后,我们制定了分析 ERF 的理论框架,从而激发了我们的可变形内核 (DK)。 我们最终在这样的框架内详细阐述了不同的 DK 变体。我们的分析表明 DK 与先前工作之间的兼容性.
3.1 深入了解卷积
2D conv 让我们首先考虑一个输入图像 $I\in \mathbb{D\times D}$。 通过将其与步长为 1 的核$W\in \mathbb{K\times K}$ 进行卷积,我们得到输出图像 O,其每个坐标$j\in \mathbb^2$处的像素值可以表示为:
在$\mathcal=[-K/2,K/2]^2\cap\mathbb$的支持下枚举出离散的卷积核位置。 这为采样数据和内核定义了一个刚性网格。
理论感受野:同一个kernel W可以重复堆叠,形成n层的线性卷积网络。 然后可以将理论感受野想象为输入图像上每个给定输出单元处内核的“累积覆盖”,通过网络反卷积。 该属性表征了一组输入字段,这些字段可以将感知触发到相应的输出像素上。 理论感受野的大小与网络深度 n 和内核大小 K 成线性关系(He et al., 2016)。
有效感受野:直观地说,并非理论感受野内的所有像素都有同等贡献。 由于堆叠卷积的中心重点以及激活引起的非线性,不同场的影响因区域而异。 因此引入了有效感受野 (ERF) (Luo et al., 2016) 的概念来测量每个输入像素对给定位置的输出的影响。 它被定义为输出相对于输入数据的偏导数字段。 通过线性卷积网络中的数值近似,ERF 先前被确定为输入图像上的类似高斯的软注意力图,其大小相对于网络深度 n 呈分数增长,并且与内核大小 K 呈线性关系。经验结果在以下情况下验证了这一想法 当网络利用非线性、跨步、填充、跳过连接和二次采样时,会出现更复杂和现实的情况。
3.2 有效感受野分析
我们的目标是重新审视和补充Luo 等人先前对ERF 的分析。 (2016 年)。 虽然前面的分析集中在研究 ERF 的期望,即当网络深度 n 接近无穷大或所有内核在没有学习的情况下随机分布时,我们的分析侧重于我们如何扰乱计算以使 ERF 的变化是可预测的 ,给定一个输入和一组内核空间。
我们通过考虑一个没有任何单元激活的线性卷积网络开始我们的分析,如第 3.1 节中所定义。 为了保持一致性,上标被引入图像 I、内核 W,而下标被引入内核位置 k 以表示索引$s\in [1,n]$的每一层。 形式上,给定一个输入图像 $I{0}$ 和一组$K\times K$内核 ${W{(s)}}_$,步长为 1,我们可以通过展开等式 1 来推出最终输出 $o\equiv I$:
根据定义1,输出坐标j取输入坐标i的有效感受野值$R(n)(i;j)\equiv\partial I_j{(n)}/\partial I_i{(0)}$可以计算为:
其中 $\mathbb{1}[.]$表示指标函数。 该结果表明 ERF 仅与数据采样位置 j、内核采样位置 k 和内核矩阵${W{(s)}}$相关。
如果我们将第 m 个内核 $W{(m)}$ 替换为从中采样的单个参数 $W_{\tilde k_m}^{(m)}$ 的 $1\times 1$内核,则 ERF 的值变为:
其中$\mathbb=[1,n] \backslash{m}$。 由于 $K\times K$核可以看作是分布在方格上的 $K^2 1\times1$ 核的组合,因此等式 3 可以重新表述为:
对于复杂非线性的情况,我们在这里考虑方程式 1 中的后 $ReLU^2$激活
我们可以进行类似的分析并得出相应的 ERF 为:
where
在这里,我们可以看到 ERF 变得依赖于数据,因为系数 C 与输入坐标、内核采样位置和输入数据 $I^{(0)}$ 相关联。 对该系数的更详细分析超出了本文的范围。 然而,应该注意的是,这个系数只是“门”输入像素对输出的贡献。 所以在实践中,ERF 是“多孔的”——有不活动的(或门控)像素单元不规则地分布在发射的像素周围。 这种现象在之前的研究中也出现过(如Luo et al. (2016),图1)。 ERF 的最大大小仍然由数据采样位置和内核值控制,如公式 5 中的线性情况。
等式 4 和等式 5 的一个很好的特性是所有计算都是线性的,使其与任何线性采样运算符兼容,用于查询分数坐标的内核值。 换句话说,采样内核实际上对线性情况下的数据进行 ERF 采样,但也粗略地推广到非线性情况。 这一发现激发了我们在第 3.3 节中设计可变形内核 (DK) 的动机。
3.3 可变形核
在等式 1 的上下文中,我们使用一组学习的核偏移重新采样核 W,表示为 ${\Delta k}$,对应于每个离散核位置 k。 我们把DK 定义为:
ERF的值为:
请注意,此操作会导致内核空间中的亚像素采样。 在实践中,我们使用双线性采样在离散内核网格内进行插值。
直观地说,原始内核空间的大小(分辨率)会影响采样性能。 具体来说,假设我们要采样一个 3 3 内核。 DK 对原始内核空间的大小没有任何限制,我们称之为 DK 的“范围大小”。 也就是说,即使采样位置的数量固定为 K2,我们也可以使用任何大小 K0 的 W。 因此,我们可以利用大内核——在我们的实验中,最大的内核可以达到 9 9,几乎没有计算开销,因为与卷积的成本相比,双线性插值非常轻量级。 这也可以增加学习参数的数量,如果处理不当,这在实践中可能会变得棘手。 在我们的实现中,我们将利用深度卷积(Howard et al., 2017),这样增加范围大小会导致可忽略不计的额外参数量。
如前所述,对内核空间进行采样实际上转换为对 ERF 进行采样。在我们学习的偏移的局部性和空间粒度的设计上,DK 自然地提供了两种变体——全局 DK 和局部 DK,如图 2 所示。在这两个算子中,我们学习了一个内核偏移生成器 G,它将输入补丁映射到 一组稍后应用于刚性内核的内核偏移量。
在实践中,我们将$\mathcal_$实现为一个全局平均池化层的堆栈,它将特征图缩减为一个向量,另一个没有非线性的全连接层将缩减的向量投影为 $2K2$维的偏移向量。 然后,我们按照公式 7 将这些偏移应用于输入图像的所有卷积。对于局部 DK,我们将 $\mathcal$实现为与目标内核具有相同配置的额外卷积,除了它只有 $2K2$个输出通道。 这会产生由输出位置 j 额外索引的内核采样偏移 ${\Delta k}$。 应该注意的是,贾等人也讨论了类似的设计。(2016)其中过滤器是从头开始生成图像或单个补丁,而不是通过重新采样.
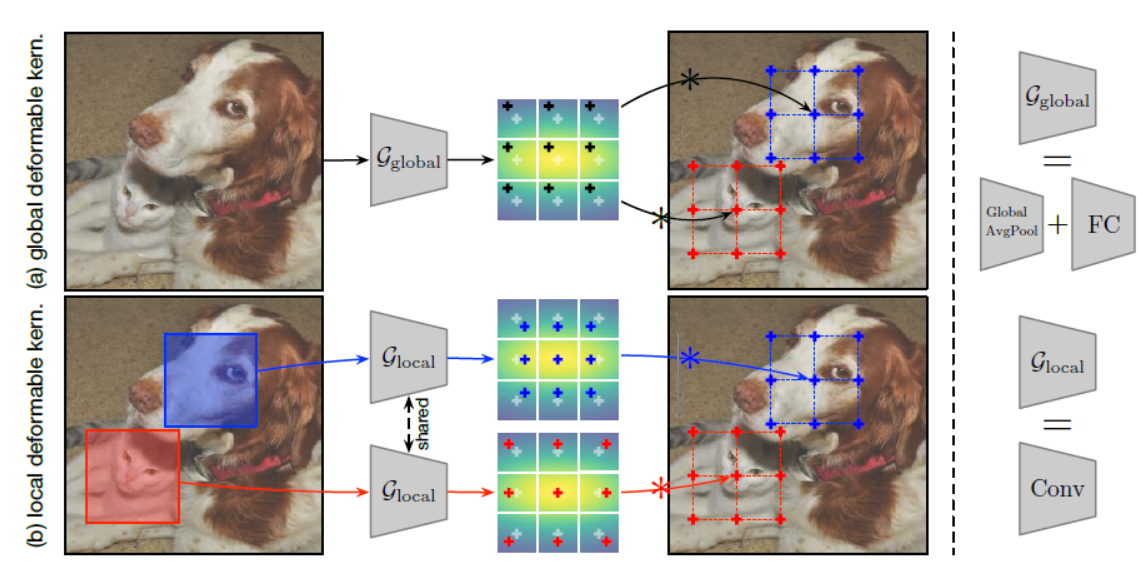
直观地说,我们期望全局 DK 能够适应不同图像之间的内核空间,而不是在单个输入中。 本地 DK 可以进一步适应特定的图像块:对于较小的对象,最好有更整形的内核,从而更密集的 ERF; 对于较大的对象,更平坦的内核可能更有利于积累更广泛的 ERF。 在较高的层次上,与全局 DK 相比,本地 DK 可以保持更好的局部性并具有更大的适应内核空间的自由度。 我们稍后会在实验中比较这些运算符。
3.4 与可变形卷积的链接
DK 的核心思想是学习自适应偏移量以对内核空间进行采样以进行变形建模,这使得它们在概念和实现层面都类似于可变形卷积(Dai 等人,2017;Zhu 等人,2019)。 在这里,我们将 DK 与可变形卷积区分开来,并展示如何将它们统一起来。可变形卷积可以以一般形式重新表述为:
他们的目标是学习一组关于离散数据位置 j 的数据偏移量 ${\Delta}$。 为了分析的一致性,有效感受野的值变为:
这种方法本质上将输入图像重构为常见模式,从而使语义识别受变形的影响较小。 此外,根据我们之前在公式 5 中的分析,采样数据是另一种采样 ERF 的方式。 这在一定程度上也解释了为什么可变形卷积非常适合学习与变形无关的表示。此外,我们可以在一个卷积算子中同时学习数据和内核偏移。 从概念上讲,这可以通过将等式 7 与等式 9 合并来完成,这导致:
我们还在实验中研究了这个算子。 尽管这两种技术可能被视为具有相似的目的,但我们发现可变形内核和可变形卷积之间的协作在实践中非常强大,这表明了强大的兼容性.
4. 实验
我们使用 ILSVRC 评估我们的可变形内核 (DK) 进行图像分类,并使用 COCO 基准进行对象检测。 提供了必要的细节来重现我们的结果,以及对所有实验和消融的基础模型和强大基线的描述。 对于特定任务的考虑,我们参考每个相应的部分。
实现细节:我们在 PyTorch 和 CUDA 中实现我们的操作符。 在设计我们的算子时,我们利用深度卷积来提高计算效率。 我们将内核网格初始化为在范围大小内均匀分布。 对于内核偏移生成器,我们将其学习率设置为主网络的一小部分,我们对每个基本模型进行交叉验证。 我们还发现在原始内核空间内裁剪采样位置很重要,例如公式 7 中的$K+\Delta k \in \mathcal$。
基础模型:我们选择我们的基础模型为 ResNet-50 (He et al., 2016) 和 MobileNetV2 (Sandler et al., 2018),遵循大多数视觉应用的标准做法。 如前所述,我们利用深度卷积,从而对 ResNet 模型进行更改。 具体来说,我们定义了我们的 ResNet-50-DW 基础模型,将所有的$3\times 3$卷积替换为其深度对应物,同时将所有残差块中的中间通道的维度加倍。 与原始 ResNet-50 相比,我们发现它是一个合理的基础模型,在两个任务上的性能相当。 在训练期间,我们将两个模型的权重衰减设置为 $4\times 10{-5}$,而不是常见的 $10{-4}$,因为深度模型通常是欠拟合而不是过拟合(Xie et al., 2017; Howard et al., 2017; Hu et al. 等人,2018)。 在我们所有的实验中,我们将 DK 算子的学习率乘数设置为 ResNet-50-DW 的 $10{-2}$ 和 MobileNet-V2 的 $10{-1}$。
强基线:我们与之前的两项工作进行了比较:用于动力学推断的条件卷积(Yang 等人,2019 年)和用于变形建模的可变形卷积(Dai 等人,2017 年;Zhu 等人,2019 年)。 由于相似的计算形式,我们选择条件卷积——采样可以被视为元素上的“专家投票”机制。 为了公平比较,我们重新实现并重现了他们的结果。 我们还将我们的运营商与这些以前的方法结合起来,以展示我们的工作机制兼容的定量证据和定性洞察力。
4.1 图像分类
我们首先在 ImageNet 2012 训练集上训练我们的网络(Deng et al., 2009)。 我们采用通用实验协议进行公平比较,如 Goyal 等人(2017);洛希洛夫和哈特 (2017)。 有关详细信息,请参阅我们的补充。
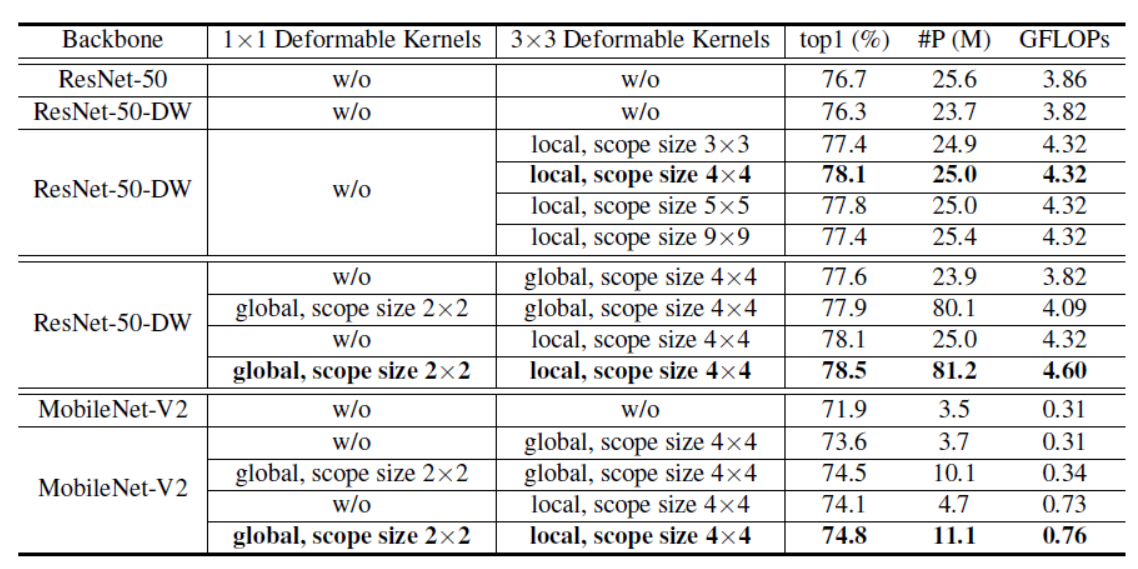
我们首先为我们的 DK 消融内核的范围大小,并使用 ResNet-50-DW 研究它如何影响模型性能。 如表 1 所示,我们的 DK 对范围大小的选择很敏感。 我们表明,当仅应用于残余瓶颈内的 $3\times 3$个卷积时,局部 DK 在原始范围内会产生 +0.7 的性能增益。 通过进一步扩大示波器尺寸,性能提高,但在$4\times 4$范围内迅速稳定,为 top-1 精度产生最大的 +1.4 增益。 我们的推测是,虽然理论上增加范围大小意味着更好的插值,但它也使每个卷积层的优化空间呈指数增长。 并且由于更新的条目数量是固定的,这也导致了相对稀疏的梯度流。 原则上,我们将 DK 的默认范围大小设置为 $4\times 4$。
接下来,我们通过将全局 DK 与本地 DK 进行比较来继续并消融我们的设计,如表中所示。 两种运营商都有帮助,而本地变体始终比全球同行表现更好,在两个基本模型上都带来了 +0.5 的差距。 我们还研究了在模型中使用更多 DK 的效果——将 $1\times 1$卷积替换为范围为 $2\times 2$的全局 $DKs^4$。请注意,所有 $1\times 1$卷积都不是深度方向的,因此该操作引入了近 4 倍的参数 . 我们将他们的结果仅用于消融,并表明添加更多 DK 仍然有帮助——尤其是对于 MobileNet-V2,因为它参数化不足。 这一发现也适用于以前的模型(Yang et al., 2019)
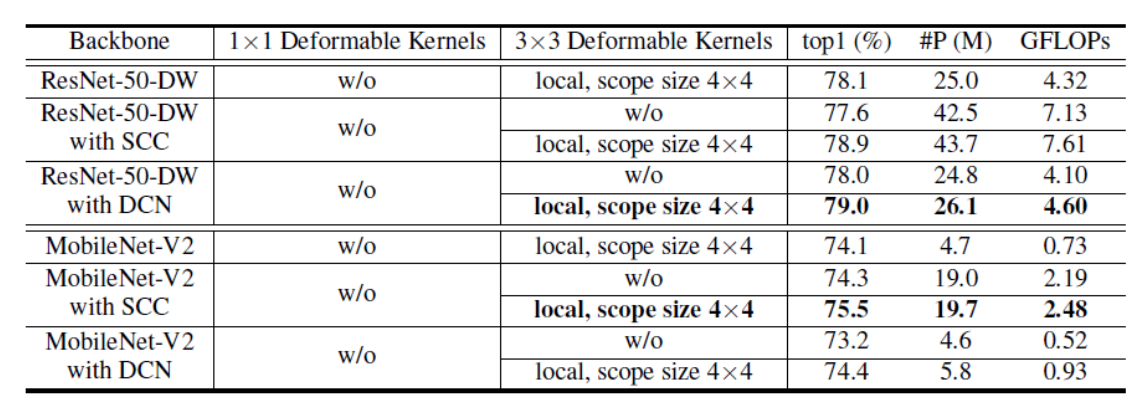
我们进一步将 DK 与条件卷积和可变形卷积进行比较和组合。结果记录在表 2 中。我们可以看到,DK 在 ResNet-V2 上的表现相当,并且在 MobileNet-V2 上的表现相当出色——与条件卷积相比,可变形卷积提高了 +0.9,并在不到四分之一的参数的情况下实现了可比较的结果。值得注意的是,我们还表明,如果结合在一起,可以获得更大的性能提升。 与强基线相比,我们看到 top-1 准确度持续提升:ResNet-50-DW 上 +1.3/+1.0,MobileNet-V2 上 +1.2/+1.2。 这些差距比我们自己的消融更大,表明运营商之间的工作机制是正交和兼容的.
4.2 目标检测
我们在 COCO 基准上检查 DKs (Lin et al., 2014)。 对于所有实验,我们使用 Faster R-CNN (Ren et al., 2015) 和 FPN (Lin et al., 2017) 作为基础检测器,插入我们之前在 ImageNet 上训练的主干。 对于 MobileNet-V2,我们将每个分辨率的特征图用于 FPN 后聚合。 按照标准协议,分别对 train-val 拆分中的 120k 图像和 test-dev 拆分中的 20k 图像进行训练和评估。为了评估,我们测量了小、中、大对象的标准平均精度 (mAP) 和破碎分数。
表 3 和表 4 遵循与图像分类相同的分析风格。 虽然 ResNet 的基线方法达到 36.6 mAP,表明基线检测器很强,但应用局部 DK 在单独替换 3x3 刚性内核时带来 +1.2 mAP 改进,当替换$1\times1和3\times 3$ 刚性内核时可以带来+1.8 mAP提升。这一趋势在 MobileNet-v2 模型上得到了放大,我们分别看到了 +1.6 mAP 和 +2.4 mAP 的改进。 结果还证实了本地 DK 对全局 DK 的有效性,这再次符合我们的预期,即本地 DK 可以更好地模拟局部性。
对于与强基线的比较,一个值得注意的有趣现象是,尽管 DK 在图像分类上的表现优于可变形卷积,但它们在通过 mAP 测量的目标检测方面明显不足。 我们推测,尽管这两种技术在理论上都可以适应 ERF(如第 3.2 节所述),但直接移动数据上的采样位置更容易优化。 然而,在将 DK 与之前的方法相结合后,我们可以持续提升所有方法的性能——每个基础模型上的可变形卷积 +0.7/+1.2,条件卷积 +1.7/+1.1。 这些发现与图像分类的结果一致。接下来,我们将研究 DK 学到了什么以及为什么它们通常与以前的方法兼容。
4.3 可变卷积核学到了什么
**物体尺度认识:**由于变形难以量化,我们使用物体尺度作为粗略的估计来了解 DK 学习什么。 在图 3 中,我们使用条件卷积和我们的 DK 通过 MobileNet-V2 中的最后一个卷积层显示了学习模型动力学的 t-SNE (Maaten & Hinton, 2008)。 我们验证了 Yang 等人声称的发现。 (2019) 条件卷积专家与对象语义的相关性比他们的尺度更好(参考他们论文中的图 6)。 相反,我们的 DK 学习与尺度而非语义密切相关的内核采样偏移。 这阐明了为什么这两个运算符在我们之前的实验中是互补的。
**有效感受野的适应:**为了验证我们关于 DK 确实在实践中适应 ERF 的说法,我们在一组图像上展示了 ERF 可视化,其中它们显示了不同程度的变形。 我们比较了刚性核、可变形卷积、我们的 DK 以及这两个算子的组合的结果。 对于所有示例,请注意理论感受野覆盖了图像中的每个像素,但 ERF 仅包含其中的中心部分。 可变形卷积 和 DK 在适应 ERF 方面表现相似,但可变形卷积倾向于分散并具有稀疏响应,而 DK 倾向于集中并在对象区域内密集激活。 将这两种运算符结合起来会产生更一致的 ERF,从而利用它们的优点