
引言
前几个星期咬咬牙把机器学习入门经典著作-周志华的西瓜话看完了,也在为知笔记上做了笔记,但是一遍总是觉得不够,所以还是决定照着书本把每一章的要点记录在博客上,当然很多细节推导肯定不会一一打公式了(毕竟太麻烦了),下面就开始第一章吧!
正文
基本术语
-
数据集(训练集、测试集)
-
样本($x_1,x_2,\cdots x_n$)
-
属性
-
有监督和无监督(有没有已知标签的训练样本)
- 有监督包括分类和回归
- 无监督包括聚类
-
分类: 对只涉及两个类别的"二分类"任务,通常称其中一个类为"正类",另一个类为"反类" (negative class); 涉及多个类别时,则称为"多分类"叫任务.一般地,预测任务是希望通过对训练集{(X1,Y1) , (X2 , Y2) ,..., (Xm, Ym)} 进行学习,建立一个从输入空间X 到输出空间y 的映射$f: x \rightarrow y$. 对二分类任务,通常令Y = {-1,+1} 或{0,1}; 对多分类任务,$|y|>2$; 对回归任务, Y= $\mathbb$,R为实数集.
-
回归:预测结果是连续值
-
聚类:把数据集自动化分为指定类别
-
泛化:在已有数据集上训练得到的模型可以很好的应用于未知数据集
假设空间
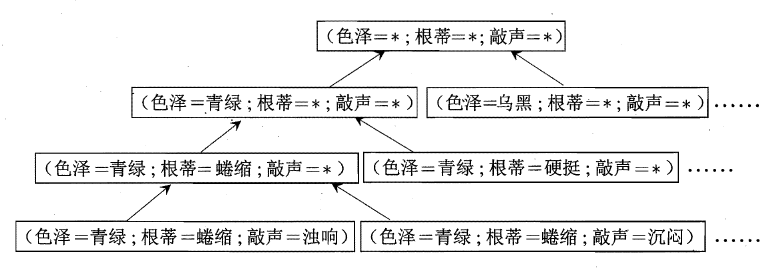
以西瓜书中判别是不是好瓜为例,可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行搜索的过程,搜索目标是找到与训练集"匹配"但t) 的假设,即能够将训练集中的瓜判断正确的假设.假设的表示一旦确定,假设空间及其规模大小就确定了.
这里我们的假设空间由形如"(色泽=?)$\Lambda$(根蒂=?)$\Lambda$(敲声=?)"的可能取值所形成的假设组成.例如色泽有"青绿" "乌黑" "浅白"这三种可能取值;还需考虑到,也许"色泽"无论取什么值都合适,我们用通配符"*"来表示,"好瓜$\leftrightarrow$(色泽= *)$\Lambda$(根蒂口蜷缩)$\Lambda$(敲声=浊响)",如下图所示显示出了这个西瓜问题假设空间.
归纳偏好
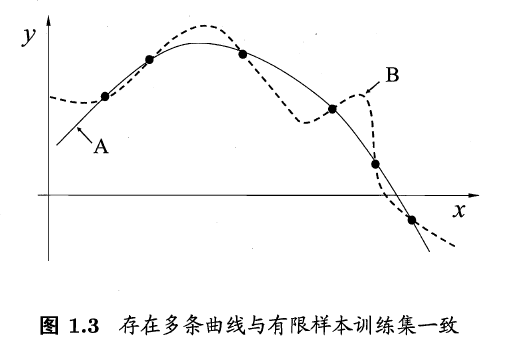
归纳偏好的作用在图1.3 这个回归学习图示中可能更直观.这里的每个训练样本是因中的一个点(x , y) , 要学得一个与训练集一致的模型,相当于找到一条穿过所有训练样本点的曲线.显然,对有限个样本点组成的训练集,存在着很多条曲线与其一致.我们的学习算法必须有某种偏好,才能产出它认为"正确"的模型
- 奥卡姆剃刀原则:若有多个假设与观察一致,则选最简单的那个
- NFL原则:考虑二分类问题,且真实目标函数可以是任何函数X$\rightarrow${0,1} ,函数空间为${0,1}^{|\chi|}$. 对所有可能的f 按均匀分布对误差求和,有:
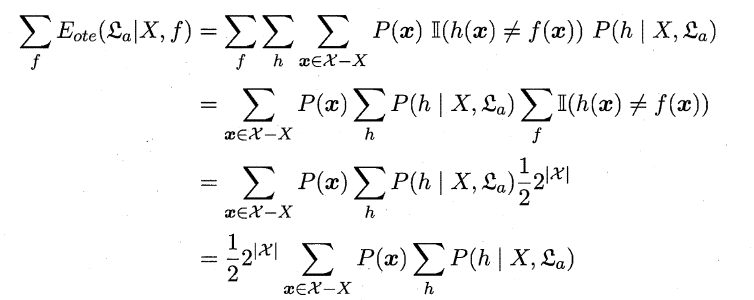
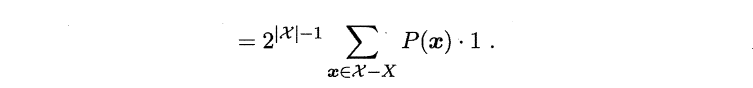
其实上面公式我也不是很懂,但是最终含义就是假设所有问题出现的机会相同或者或所有问题同等重要,这时所有算法的效果几乎相同。NFL定理最重要的意义是让我们清楚地认识到,脱离具体问题,空泛地谈论"什么学习算法更好"毫无意义,因为若考虑所有潜在的问题,所有学习算法都一样好.要谈论算法的相对优劣,必须要针对具体的学习问题;在某些问题上表现好的学习算法,在另一些问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否相配,往往会起到决定性的作用.
结语
若你以为每一章都这么简单就大错特错了