
引言
接下来我将对自己看过的一些论文边看边做markdown笔记,希望和大家一起学习,一起进步!
正文
One-Stage和Two-Stage
目标检测是计算机视觉领域非常重要的一个分支,其主要目的就是在图片数据集中识别出指定的物体类别并且可以标定出物体的位置,其主要算法可以分成One-Stage和Two-Stage两种类别,其中Two-Stage以R-CNN算法为代表,先生成候选区域对原始图片进行局部化和分割(如RPN),二是对分割后的小区域提取特征,然后送入分类器进行判别,再送入回归器修正回归框位置,One-Stage以YOLO系列算法为代表,其主要思路是只需经过一个网络就可以同时输出类别和位置信息,可想而知,Two-Stage算法计算量比One-Stage算法大,精度相对更高,速度相对更慢。
YOLOV1
YOLOV1正式标志着YOLO系列的开端,YOLO系列算法虽然精度没有Faster R-CNN高,但是注重的是速度和准确率的权衡,因此在实际工程应用中还是得到了广泛应用。
网络结构
YOLOV1网络结构借鉴了GoogleNet,包含24个卷积层,2个全链接层。
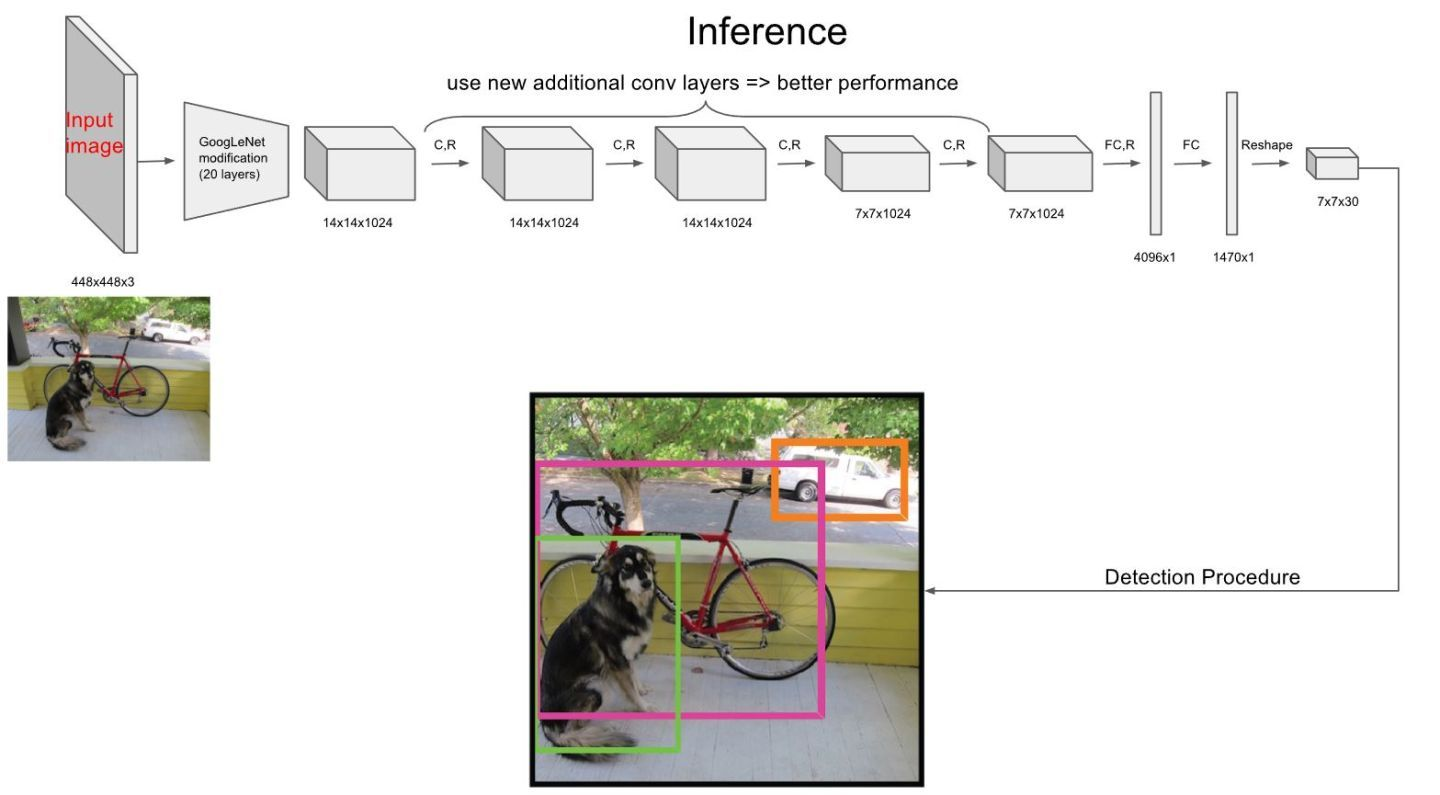
输入:448 x 448 x 3,由于网络的最后需要接入两个全连接层,全连接层需要固定尺寸的输入,尺寸不同需要resize(这也是一个缺点)
中间:
论文中的网络截图如图所示:
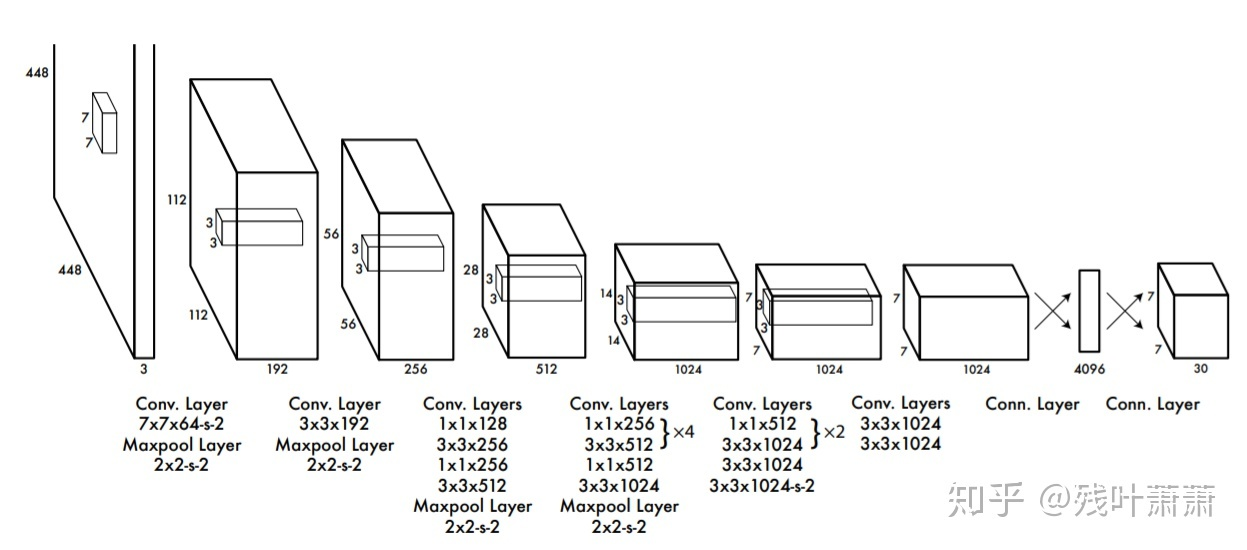
前20层中用1×1 reduction layers 紧跟 3×3 convolutional layers 取代GooLeNet的 inception modules,可以参考以下结构图:
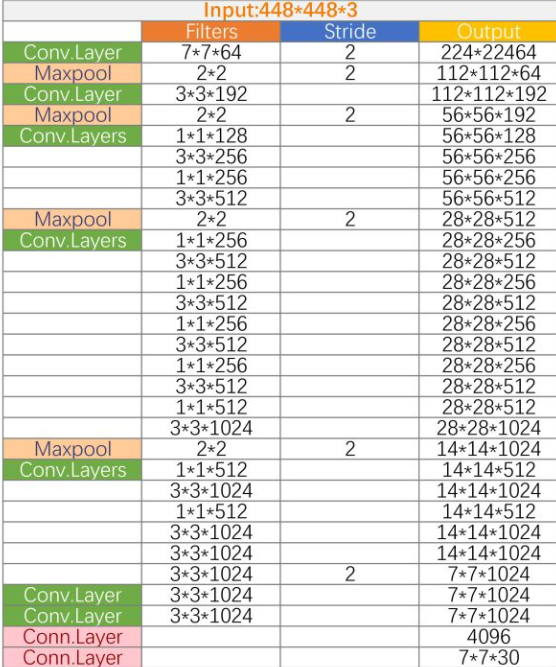
网上还有大神直接用卷积层计算公式计算出每一层的输入输出,大家可以看看:
对计算公式不懂的可以参考以下公式(不想自己打了,直接截图吧):

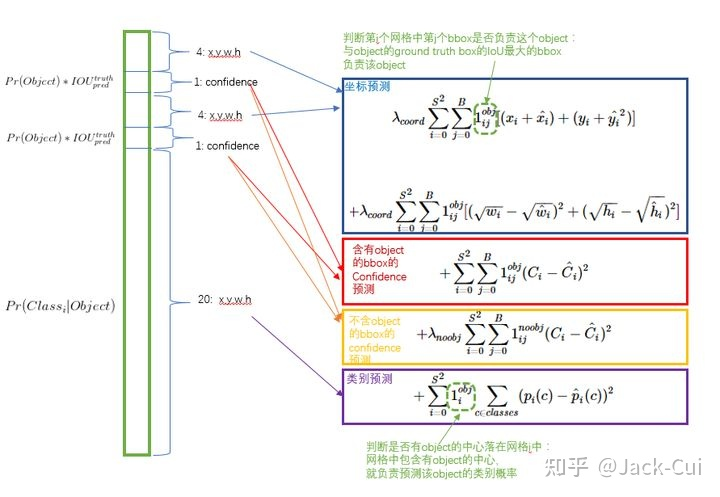
输出: 最后一个FC层得到一个1470 x 1的输出,将这个输出reshap一下,得到 7 x 7 x 30 的一个tensor,即最终每个单元格都有一个30维的输出,代表预测结果,包含20个对象的概率+两个bounding box(bbox)的位置(每个位置由4个参数表示共8个)+两个bbox的置信度
tricks
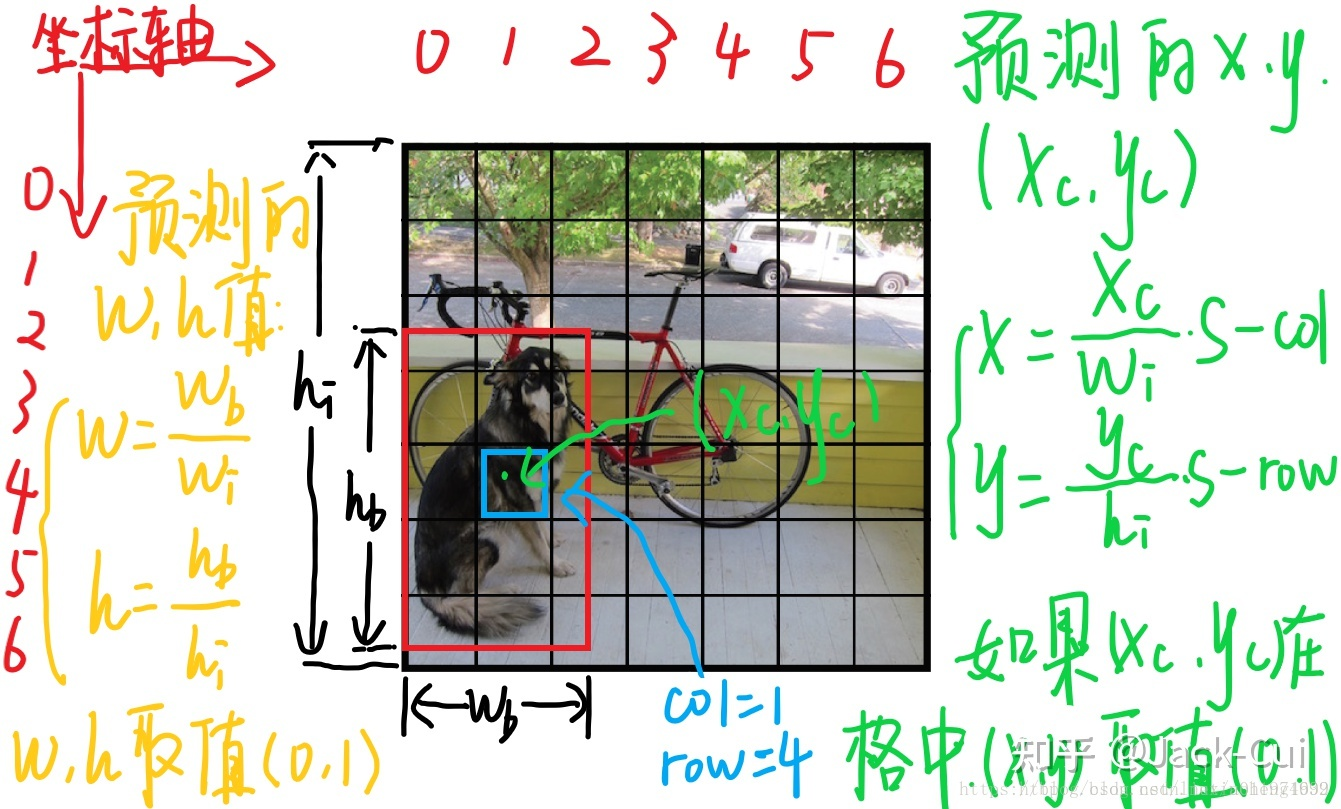
7x7网格:输入图像要划分成7x7个单元格,输出也是7x7个单元格,对应原图像,每个单元格输出30维预测结果,但并不是说仅仅网格内的信息被映射到一个30维向量。经过神经网络对输入图像信息的提取和变换,网格周边的信息也会被识别和整理,最后编码到那个30维向量中,在Yolo中,如果一个物体的中心点,落在了某个格子中,那么这个格子将负责预测这个物体,用下图举例,设左下角格子假设坐标为 (1,1),小狗所在的最小包围矩形框的中心,落在了 (2,3) 这个格子中。那么7*7个格子中,(2,3)这个格子负责预测小狗,而那些没有物体中心点落进来的格子,则不负责预测任何物体,这种划分策略相对于一开始就指定了共有49个检测人员,每个人员负责检测一个物体,大家的分工界线,就是看被检测物体的中心点落在谁的格子里。

30维输出:
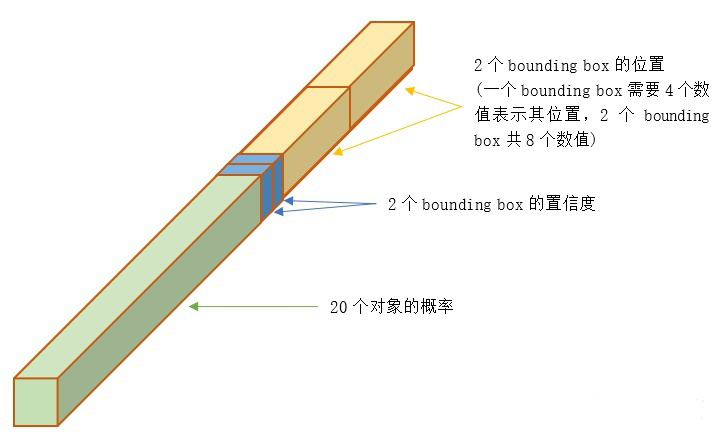
- 2个bbox位置:对于每个单元格,YOLOv1会预测出2个bounding box,每个bounding box需要4个数值(x, y, w, h)来表示其位置,2个bounding box共需要8个数值来表示其位置。$(x_c,y_c)$是bbox的中心点的位置,这个位置值相对于单元格归一化到0-1之间,例如图片的宽为width,高为height,那么输出的(x,y)计算公式如下:
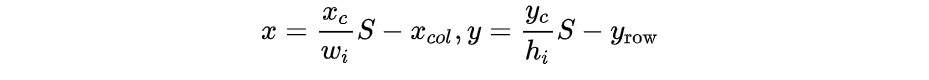
其中wi为物体实际宽度,hi为物体实际高度,S为网格划分数目,这里是7x7所以S就是7,$x_$是回归框中心所在单元格的列数,$y_$是回归框中心所在单元格的行数,w, h是预测的回归框相比较于物体宽高的比例,也在0-1之间
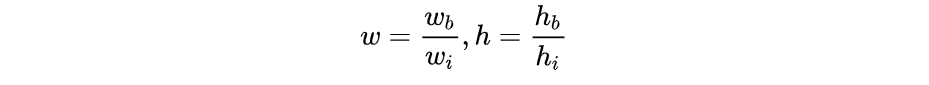
网上还有大神给出了更详细的例子,给这位大神点个赞!
- 置信度
这个置信度是由两部分组成,一是格子内是否有目标,二是bbox的准确度。定义置信度为:$P_r(object)*IOU^_$
物体属于第i类的置信度计算公式为:
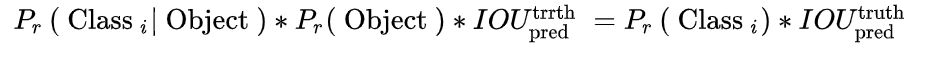
- Loss
YOLOV1的Loss函数计算比较复杂,公式如下所示,也可以参考网上大神给出的详细解释示意图:
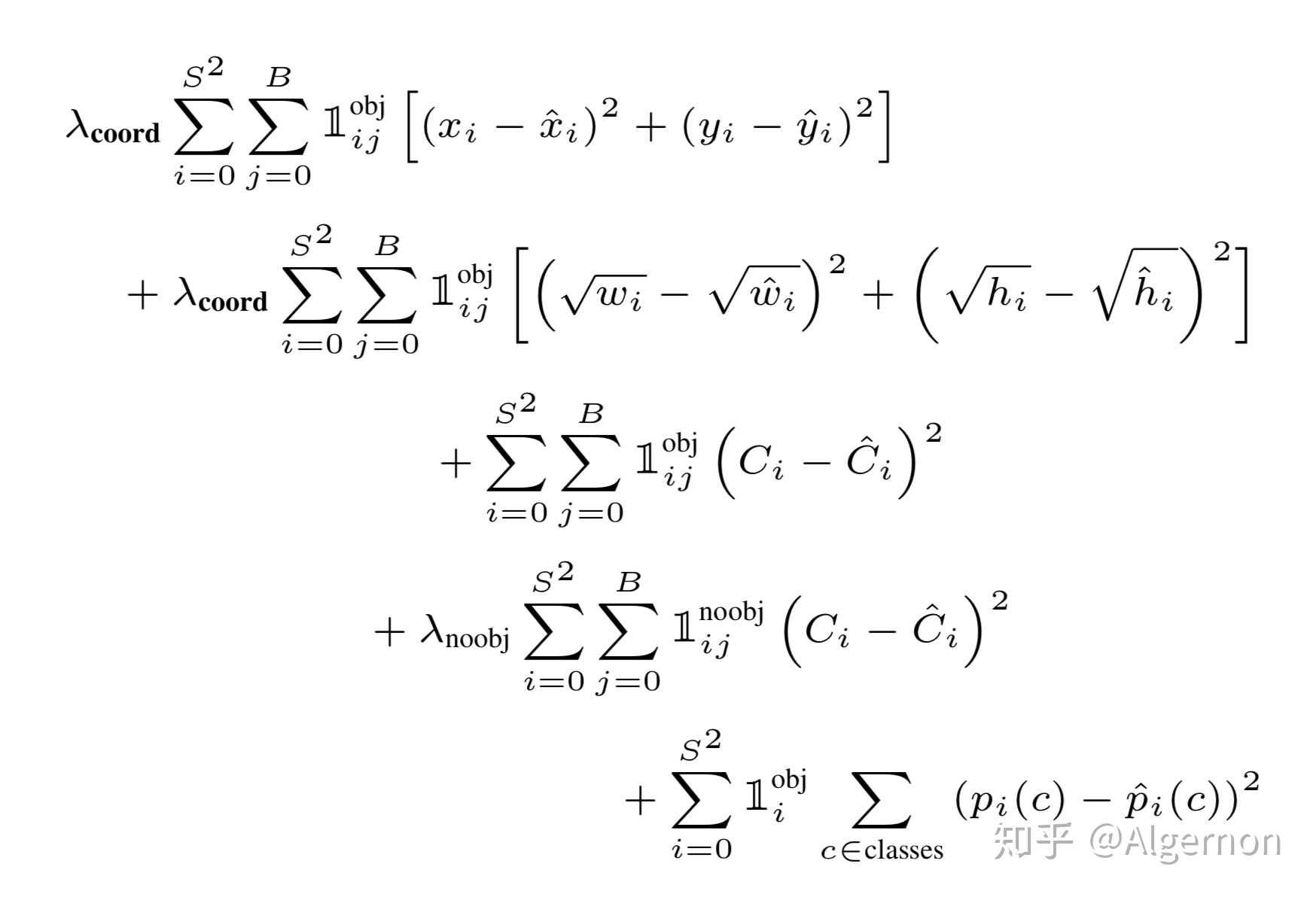
- (x,y) Loss
其中公式第一行表示预测框中心点(x,y)造成的损失,其中$1_^$表示第i个单元格的第j个bbox是否包含物体,包含为1,不包含为0。 - (w,h)Loss
公式第二行表示预测框宽高(w,h)造成的损失。$1_^$的含义和和上面一样,也是使得只有真实物体所属的格点才会造成损失。这里对(w,h)在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。 - 置信度 Loss
公式第三行和第四行表示含有物体和不含物体的bbox置信度预测,当该格点不含有物体时,$1_^$=1,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(IOU计算公式为:两个框交集的面积除以并集的面积) - 物体类别 Loss
公式最后一行输出的是物体类别概率,输出类别对应标签为1,其他为0
- (x,y) Loss
- NMS
NMS称为非极大抑制,主要目的是去除一些冗余框,如下图所示:

- IOU
上面已经提到了IOU,下面就给出IOU计算公式:
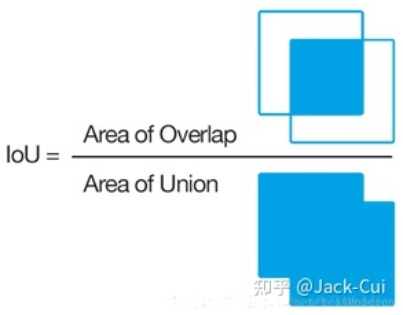
也就是重叠区域面积/总面积 - NMS思路
- 假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F
- 从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值
- 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的
- 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框
- 就这样一直重复,找到所有被保留下来的矩形框
- IOU
总结
YOLOV1虽然现在已经很少有人问津,但是引入的IOU、NMS等机制为后续的系列留下了很多改进思路,值得我们去阅读!
每日一语
我想吃外卖!!